
[CV] CNNs for Visual Object Tracking
The previous post was about some introduction about object tracking and two approaches in single object tracking. Among others, discriminative tracking, or tracking-by-detection formulates the object tracking as a sequential binary classification (object detection) model. And we discussed the application of deep learning to the detection in object tracking at the last part of the post. In this post, we keep diving into deep learning approaches for object tracking. We will discuss about one representative idea called Siamese networks and three more advanced models built on top of that model.
Introduction
Our objective is to build a model that identify the target at the current frame. If $\mathbf{x}$ denotes the candidates for the target and $\mathbf{x}^*$ is the ground truth, we want a classifier $f$ that
\[\begin{aligned} \mathbf{x}^* = \underset{\mathbf{x}}{\text{argmax }} f(\mathbf{x}) \end{aligned}\]The most critical part here in non-deep learning approaches was how can we represent the object and extract useful feature. But it is not much problem with deep learning, as the model learns to extract the feature itself by end-to-end manner, and it turned out that the automatically extracted feature by model is much better than hand-designed features in various areas.
The visual object tracking is not an exception, too. As we saw in the previous post, Hong, Seunghoon, et al. already proves that employing pre-trained feature alone gives us descent improvement and outperforms the previous hand-crafted solutions.
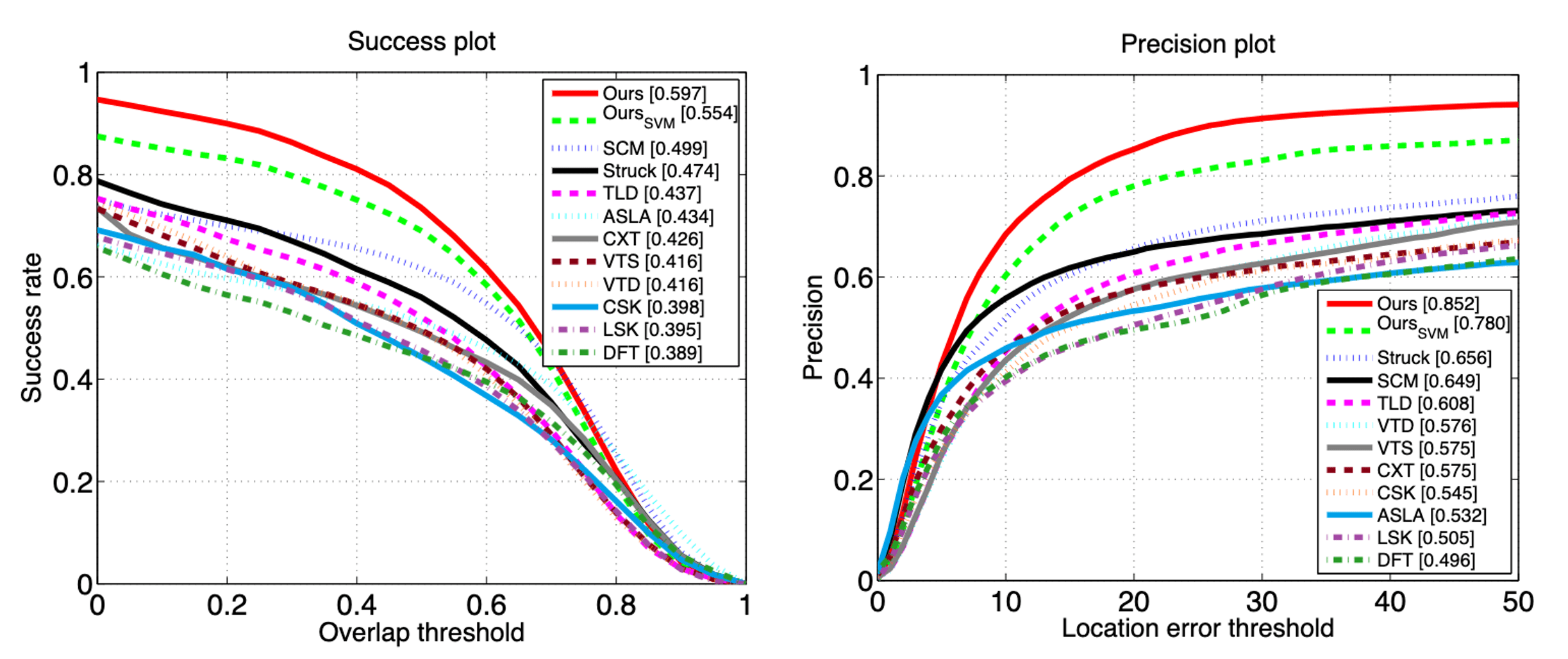
$\mathbf{Fig\ 1.}$ Success of CNN in visual object tracking (source: Hong, Seunghoon, et al.)
But the major problem is that the model (classification) should solve the one-shot classification problem, since the ground-truth for target is only given at the initial frame in object tracking task. Also, in the worst case, the target is possible to be modified for every frame. Then how do we build a classifier that basically distinguish all these different objects and how to train such classifiers with only a single frame annotation?
As an example, Hong, Seunghoon, et al. applied online SVM to the framework: at the very first frame, SVM is just trained with just a single label given in the frame. And as we apply the classifier, we get some new tracking results in the next new frames.
These tracking results are considered as another sample to feed the classifier (self-supervised). Hence the application of the classifier and the training of it happens simultaneously during the tracking. However, it can easily overfit because the data for the classifier is only given at the initial frame and can be prone to be wrong in case of temporal misclassification.
![]()
$\mathbf{Fig\ 2.}$ Example of training the classifier: online tracking (source: Hong, Seunghoon, et al.)
SiamFC (ECCV 2016)
Actually, offline training and online deployment is a standard concept in CNN model, for instance, in image classification. The model is just trained based on the training dataset, and we just apply this trained model in the test time, without any learning.
However, in tracking, the classifier cannot be transferred across videos since the definition of foreground/background are different in every videos, i.e., tracking targets are different in all videos. Then how can we design a classifier transferable across different targets?
Discriminative tracking via exemplar classifier
We are going to modify the parameterization of the classification into:
\[\begin{aligned} \mathbf{x}^* = \underset{\mathbf{x}}{\text{argmax }} f ( \phi( \mathbf{x})) \quad \text{ where } \quad f = \psi (\mathbf{z}) \end{aligned}\]and $\phi$ is a feature extractor and $\mathbf{z}$ is an initial target given in the first frame. By formulating the classifier to be function of initial target in the first frame, now we can pre-train the classifier parameters $\psi$ across different videos. If we train this model $\psi$ with various videos, it learns-to-encode arbitrary target such that the similarity with the ground-truth $\mathbf{x}^*$ is higher than the rest $\mathbf{x}$ into the classifier. Hence, it is transferable across different videos and targets.
And if $\psi = \phi$, then we call this as Siamese network, i.e. feature extractor and classifier are equivalent.
Fully-convolutional Siamese network
SiamFC (Fully-convolutional Siamese network, Bertinetto et al.) implements the extractor and classifier with fully-convolutional networks.
Let $z$ be a target in initial frame, and $x$ be any new frame. Denote the fully-convolutional Siamese network by $\phi$. Considering the feature of the target as a filter, run convolution on entire feature map of the frame i.e. $\phi(\mathbf{z}) * \phi(\mathbf{x})$. Finally, it outputs the score map of the target densely computed in every location.
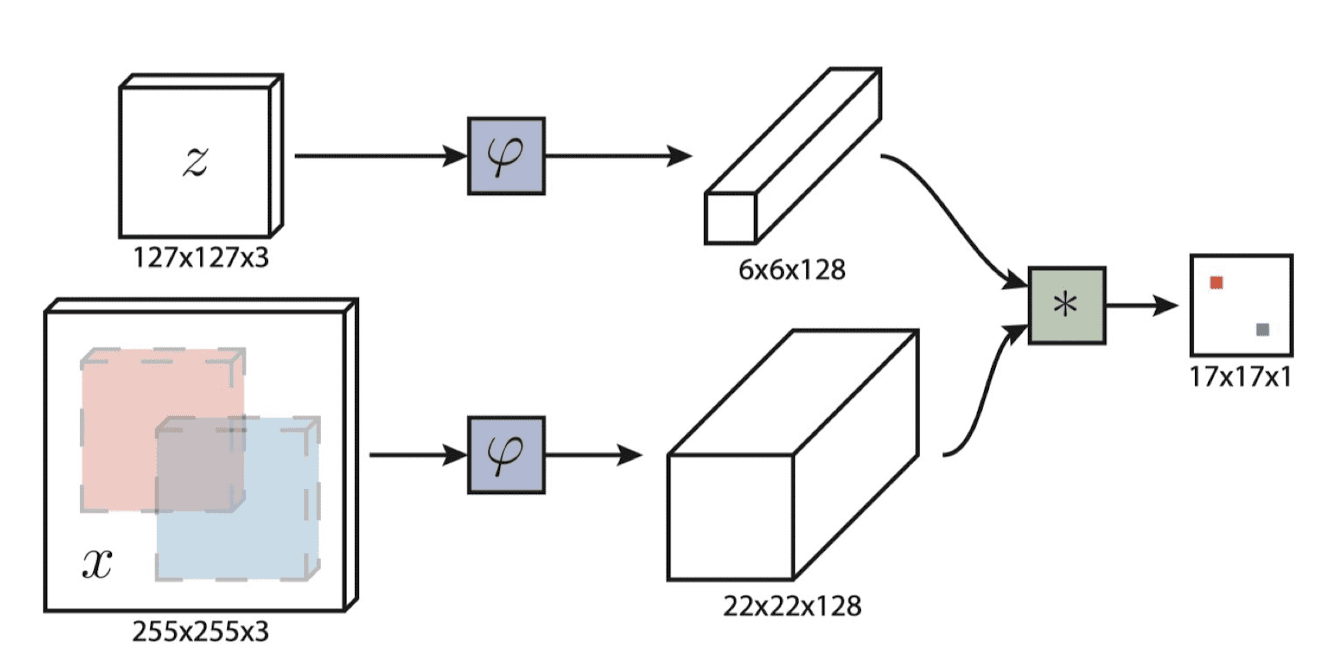
$\mathbf{Fig\ 3.}$ Bertinetto et al., Fully-convolutional Siamese network
Training details are outlined below. Note that it still follows end-to-end learning, the gradient of shared parameter will be accumulated from the both side.
-
Dataset
- ImageNet Video dataset
-
Training algorithm
- For each video, sample two frames with sufficient time interval $T$
- one frame to extract the target $\mathbf{z}$ and the other as a candidate $\mathbf{x}$
-
for each position $u \in \mathcal{D}$ in the score map $y$, build a soft ground-truth
\(\begin{aligned} y[u] = \begin{cases} + 1 \quad& \text{ if } k \| u - c \| \leq R \\ - 1 \quad& \text{ otherwise } \\ \end{cases} \end{aligned}\)
where $c$ is the ground-truth location of the target, $k$ is the stride of network, and $R$ is radius
- For each video, sample two frames with sufficient time interval $T$
-
Loss $L$
- logistic loss for target $y$ and prediction $v$
\(\begin{aligned} L(u, v) = \frac{1}{| \mathcal{D} |} \sum_{u \in \mathcal{D}} \ell(y[u], v[u]) = \frac{1}{| \mathcal{D} |} \sum_{u \in \mathcal{D}} \text{ log } (1 + \text{exp } (-y[u] \cdot v[u])) \end{aligned}\)
- logistic loss for target $y$ and prediction $v$

$\mathbf{Fig\ 4.}$ Examples of training pair of SiamFC extracted from the same video (source: Bertinetto et al.)
Once we train our model with a lot of different videos, we just apply the model in the inference time without any online learning. Oneline update of the target feature $\psi (\mathbf{z})$ is straightforward, but it didn’t get the gain.
Summary
Despite its simplicity, it approached or improves other state-of-the-art real-time trackers in the challenging VOT-15 benchmark while being the only one that achieves real-time speed. (Because all operations in the model are convolution, which is GPU-friendly)
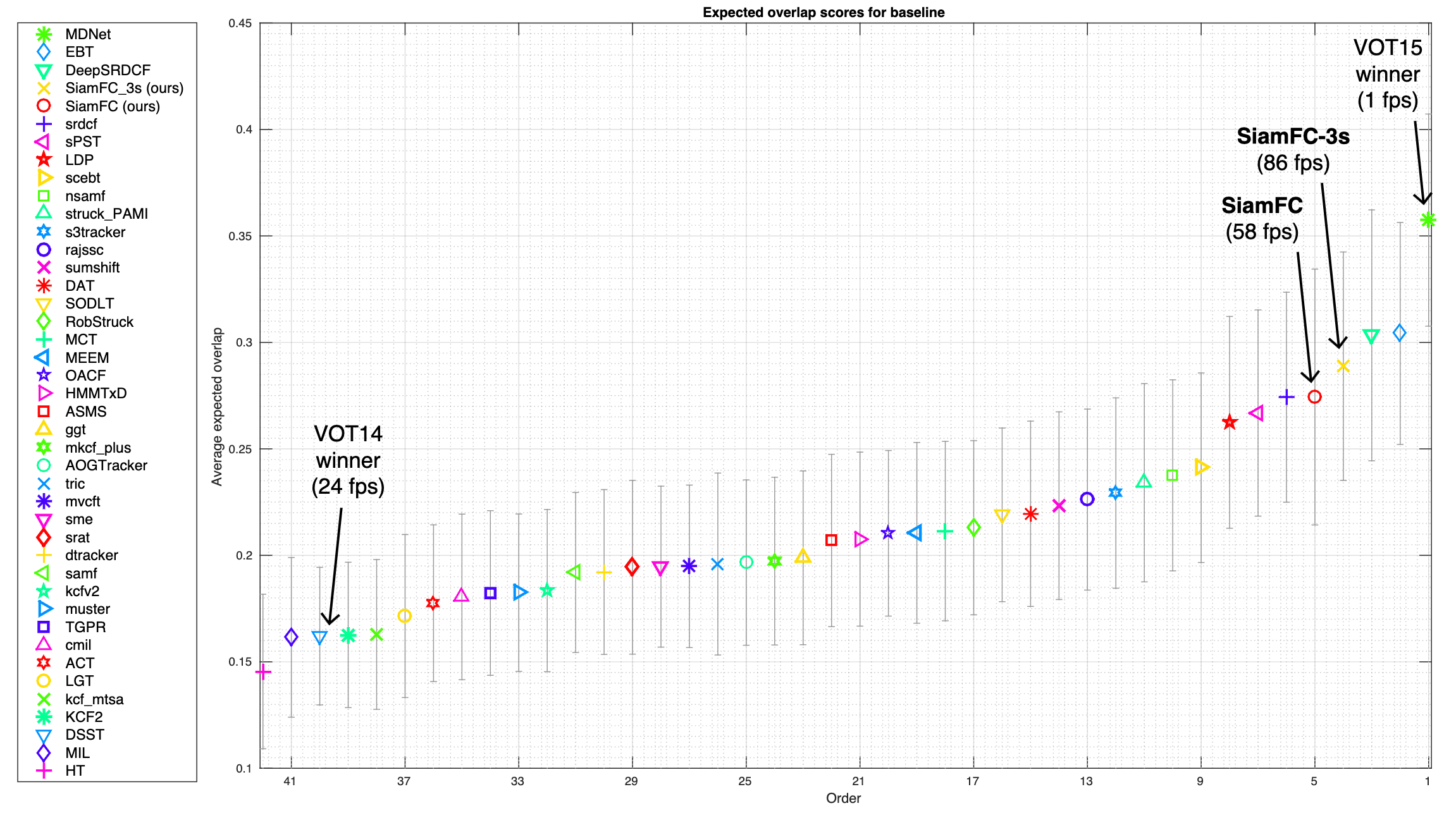
$\mathbf{Fig\ 5.}$ VOT-15 ranking of the best 40 results (source: Bertinetto et al.)
In short, the characteristics and advantages of SiamFC can be summarized as
- Discriminative tracking via exemplar classifier
- Use the target at initial frame as a convolution filter = adaptable classifier
- The entire model is pre-trained end-to-end and transferable across videos
- Can be deployed to videos with arbitrary target in testing time
- Fully-convolutional Siamese network
- Both the target classifier and frame-level feature extractor share the same parameters
- Produces a score map via filtering, which allows super-efficient examination of samples
- Fast, and reasonably accurate
- Real-time performance (60~80 fps)
SiamRPN (CVPR 2018)
In SiamFC, only the scale variation is modeled via image pyramid. If we want to model variations in more scales and aspect-ratio, exhaustive search (image pyramid) is not efficient. SiamRPN (Siamese Region Proposal network, Li et al. CVPR 2018) exploits the region-proposal netowork in order for efficient search over scale and aspect ratio.
It attached region-proposal network (proposed in Faster R-CNN) for $k$ number of proposals, after extracting feature from template frame and detection frame. Finally it outputs $k$ number (along the channel dimension) of score map where $k$ is for several scales. After these operations, the top $K$ proposals are ranked and non-maximum-suppression (NMS) is performed to get the final tracking bounding box.
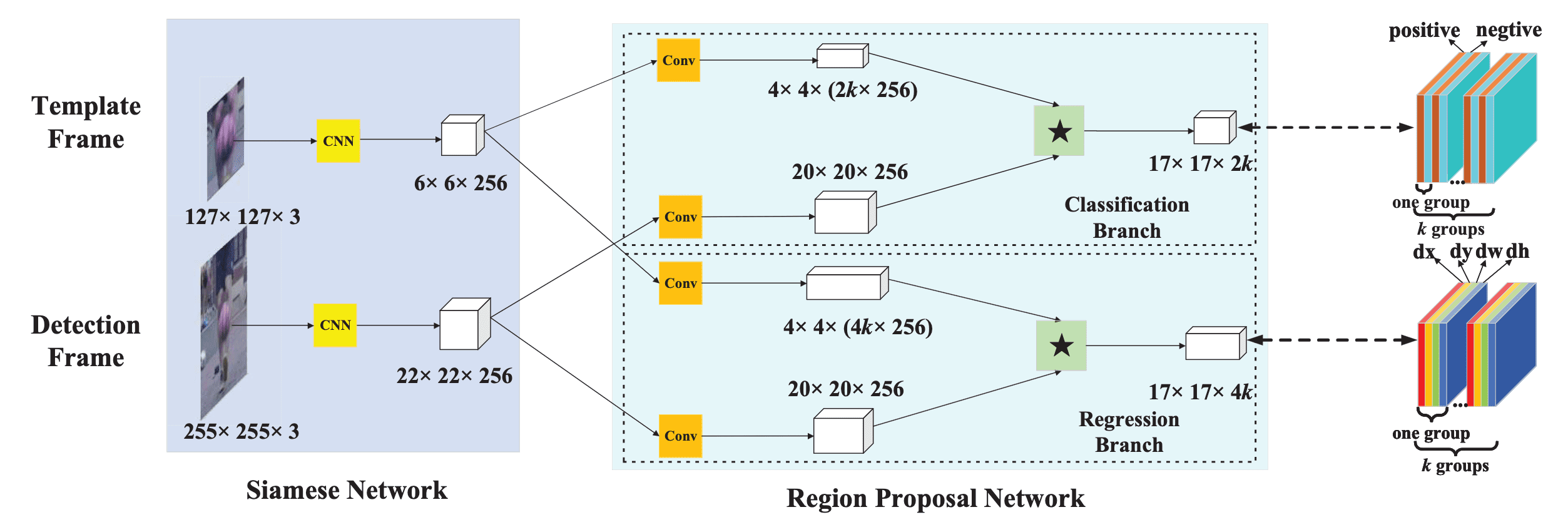
$\mathbf{Fig\ 6.}$ Li et al., Siamese Region Proposal Network
As a result, it outperforms the state-of-the-art tracker and is able to conduct at 160 FPS which is nearly two times of Siamese-FC:
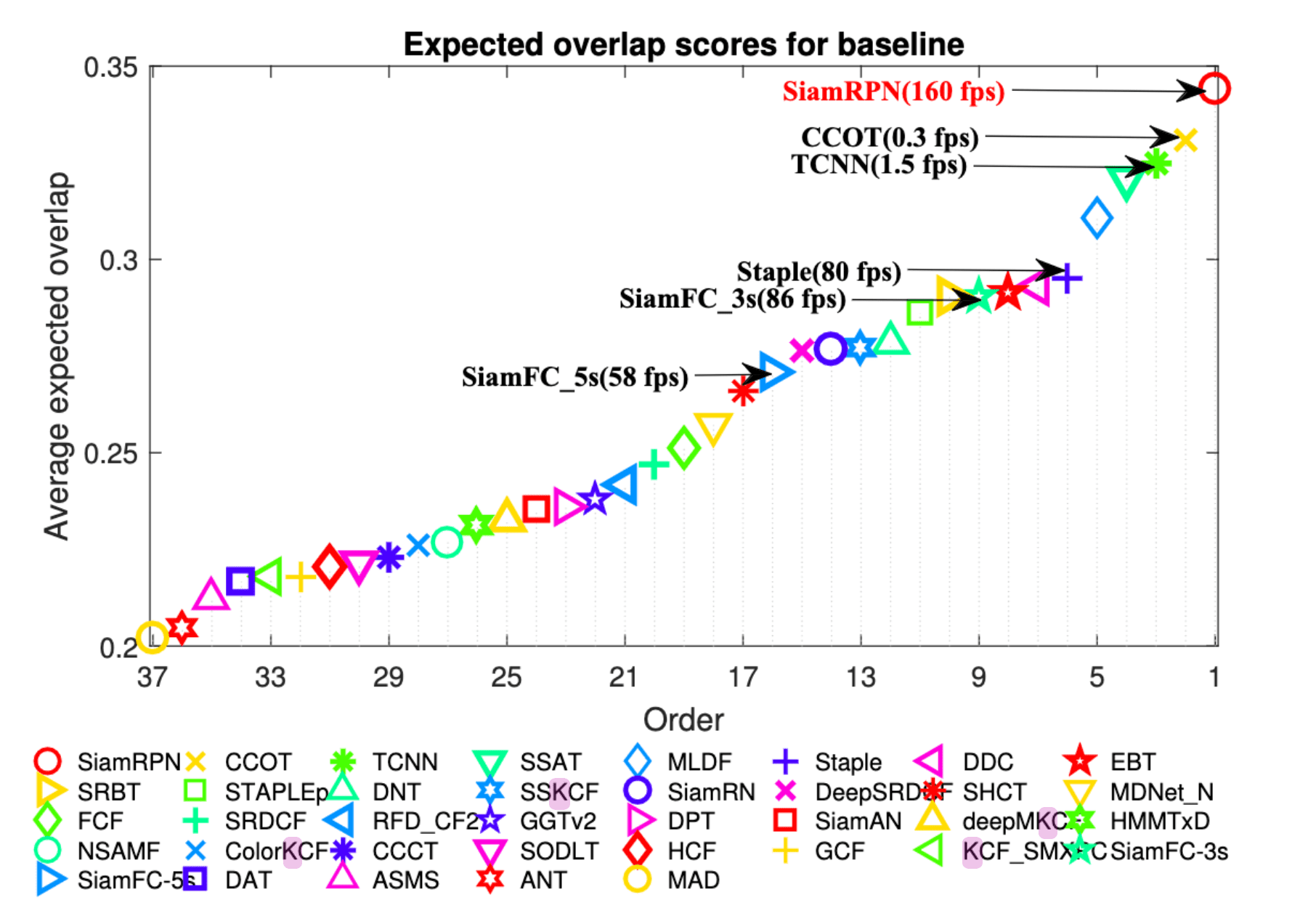
$\mathbf{Fig\ 7.}$ VOT-16 ranking (source: Li et al. 2018.)
SiamRPN++ (CVPR 2019)
SiamRPN++ is an improved version of SiamRPN, proposed by same authors. To measure the score for $k$ number of bounding boxes in SiamRPN, it essentially creates the score map for $k$ number of proposals, leading to the gigantic number of channels (depths).
To discard the burden, instead of normal convolutions used in Siamese network ((a) in $\mathbf{Fig\ 8.}$) and region proposal network ((b) in $\mathbf{Fig\ 8.}$), SiamRPN++ employs channel-wise convolution, or depth-wise convolution which can greatly reduce the computational cost and the memory usage, but give us the same set of outputs.
Obviously, this can sacrifice the expressive power since the convolution filter is now the single channel convolution. To compensate the limited expressive power, the authors also proposed the ResNet-driven deep networks. It’s hierarchically implemented with multiple feature levels and skip connections.
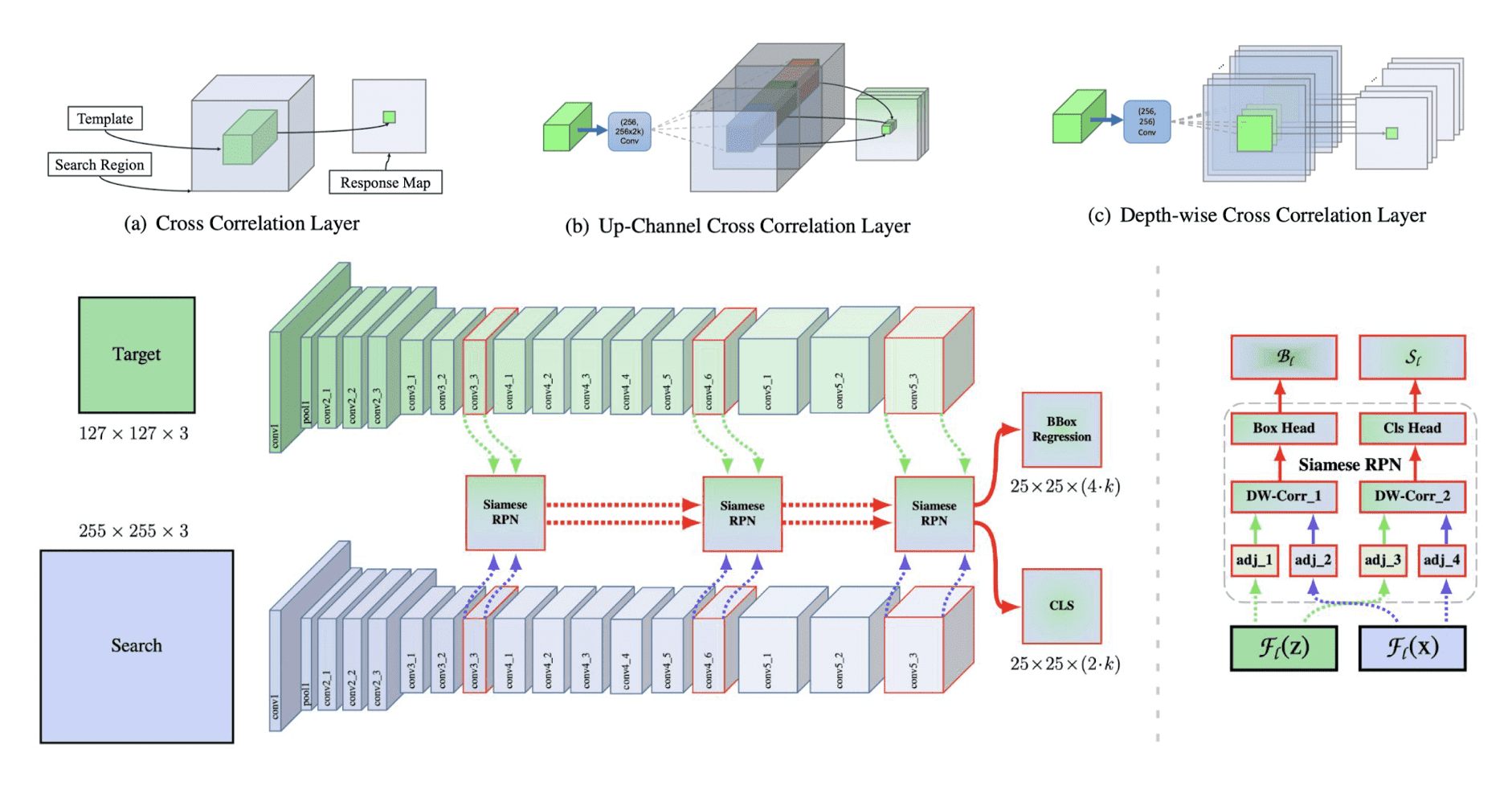
$\mathbf{Fig\ 8.}$ SiamRPN++ (source: Li et al. 2019.)
SiamMask (CVPR 2019)
Thus far, we are considering the single object tracking task as a binary classification with bounding box score, where it is too coarse labeling. Instead, SiamMask (Wang, Qiang, et al. CVPR 2019) also predicts the binary mask pixel-wisely together with the bounding box. And by predicting the pixel-wise loss, it maybe give the model a better sense of localization.
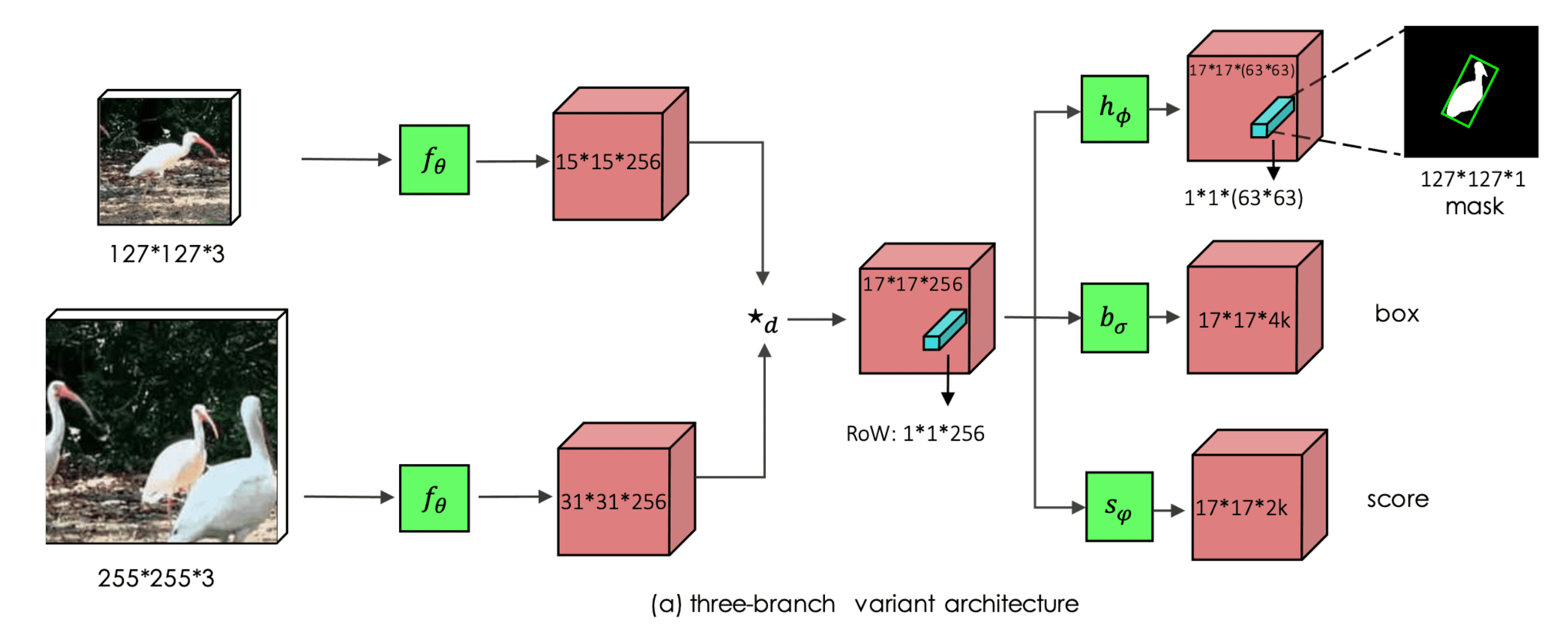
$\mathbf{Fig\ 9.}$ Wang, Qiang, et al., SiamMask
As we expect, it basically improves the accuracy mainly because the learning signal is more fine-grained and the model can not only create the bounding box but also the segmentation mask which gives further accuracy in localization.
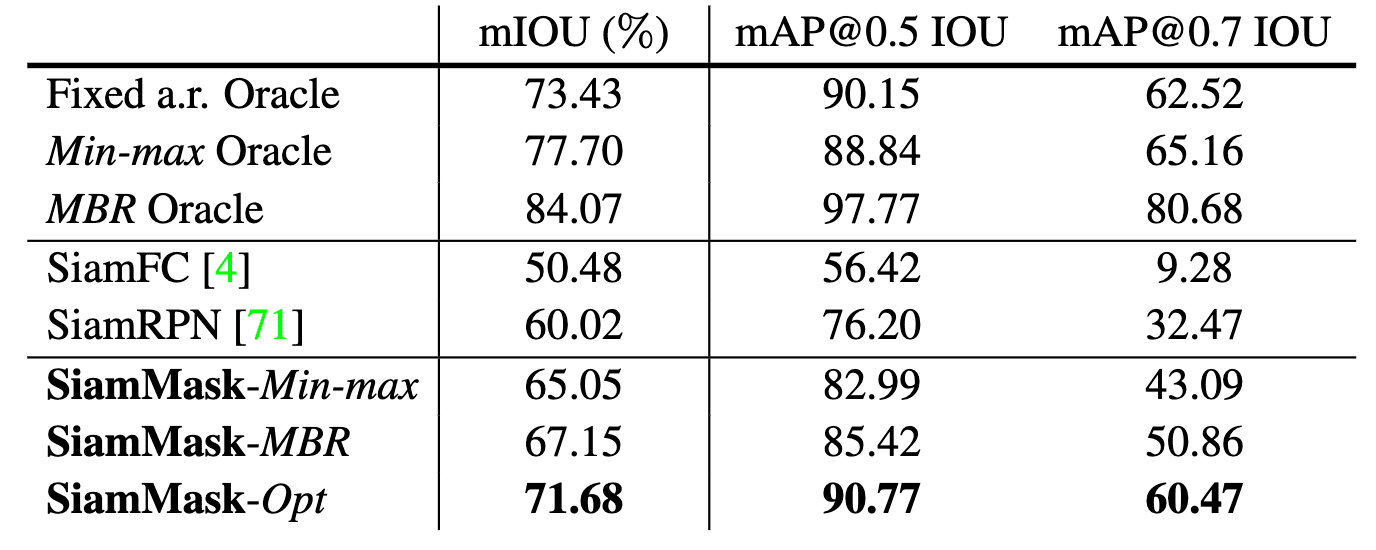
$\mathbf{Fig\ 10.}$ Performance table for VOT-16 (source: Wang, Qiang, et al.)
And here are some examples of tracking result of SiamMask:

$\mathbf{Fig\ 11.}$ Qualitative result of SiamMask (source: Wang, Qiang, et al.)
Reference
[1] Stanford University CS231B: The Cutting Edge of Computer Vision, Spring 2015
[2] Hong, Seunghoon, et al. “Online tracking by learning discriminative saliency map with convolutional neural network.” International conference on machine learning. PMLR, 2015.
[3] Bertinetto et al., Fully-Convolutional Siamese Networks for Object Tracking, ECCV 2016.
[4] Li et al., High Performance Visual Tracking with Siamese Region Proposal Network, CVPR 2018.
[5] Li et al., SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks, CVPR 2019.
[6] Wang, Qiang, et al., Fast Online Object Tracking and Segmentation: A Unifying Approach, CVPR 2019.
Leave a comment