
[CV] Scaling Vision Models by Image Scales
Scaling up model size has been a significant factor driving recent advances in various domains of AI, and computer vision is no exception. Larger models and datasets have consistently demonstrated improvements across a broad range of downstream task. However, against such trend, Shi et al., 2024 explored whether larger vision models are not necessary; by scaling vision models on multiple image scales.
S2: Scaling on Scales
Instead of scaling up model size, the authors rather considered scaling on the dimension of image scales, proposing Scaling on Sales (S2). Surprisingly, they observed a smaller vision model scaled by S2 often gives comparable or better performance than larger models.
Regular vision models are normally pre-trained at a single image scale (e.g., $224^2$). S2-Wrapper extends a pre-trained model to multiple image scales (e.g. $448^2$, interpolated from $224^2$).
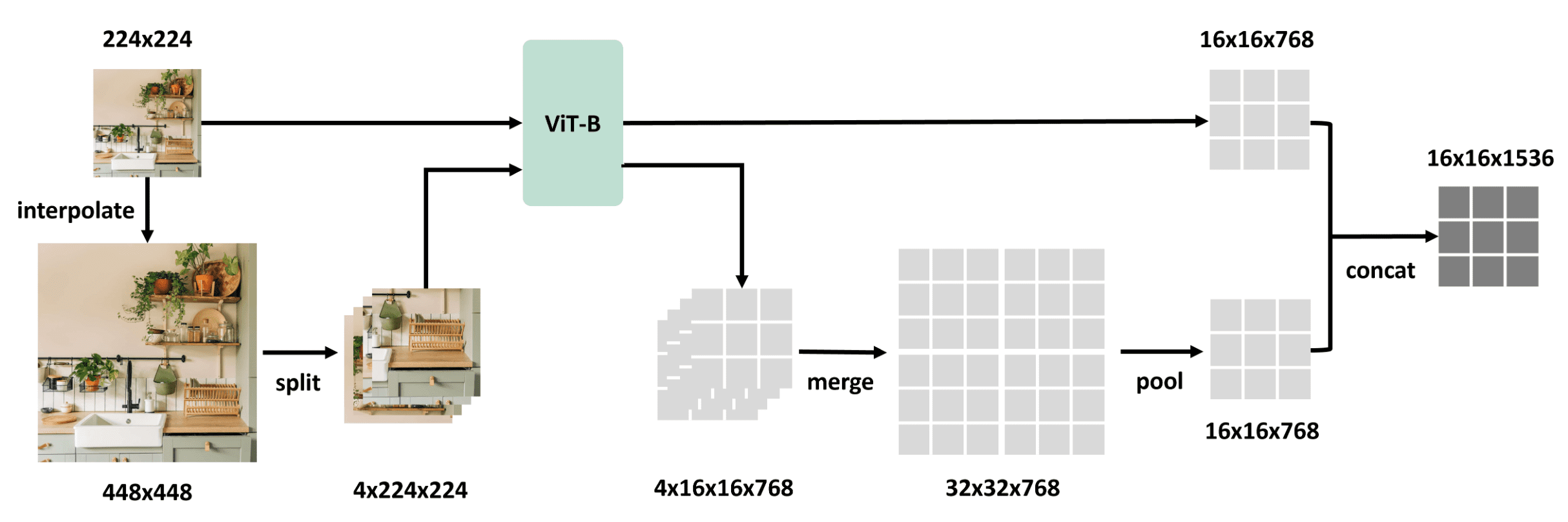
S2-Wrapper is designed as a parameter-free, model-agnostic mechanism that enables multi-scale feature extraction on any pre-trained vision model. It consists of 3 key components:
- Splitting
To avoid quadratic computation complexity in self-attention and prevents performance degradation caused by position embedding interpolation, it splits $448^2$ image into 4 $224^2$ images. - Individual processing of sub-images
All $224^2$ images are individually processed by vision model to avoid training additional parameters or the necessity of special designs of vision model. - Average Pooling
The features of $4$ sub-images are merged back to the large feature map of the $448^2$ image, which is then average-pooled to the same size as the feature map of $224^2$ image. This ensures the number of output tokens stays the same, preventing computational overhead in downstream applications.
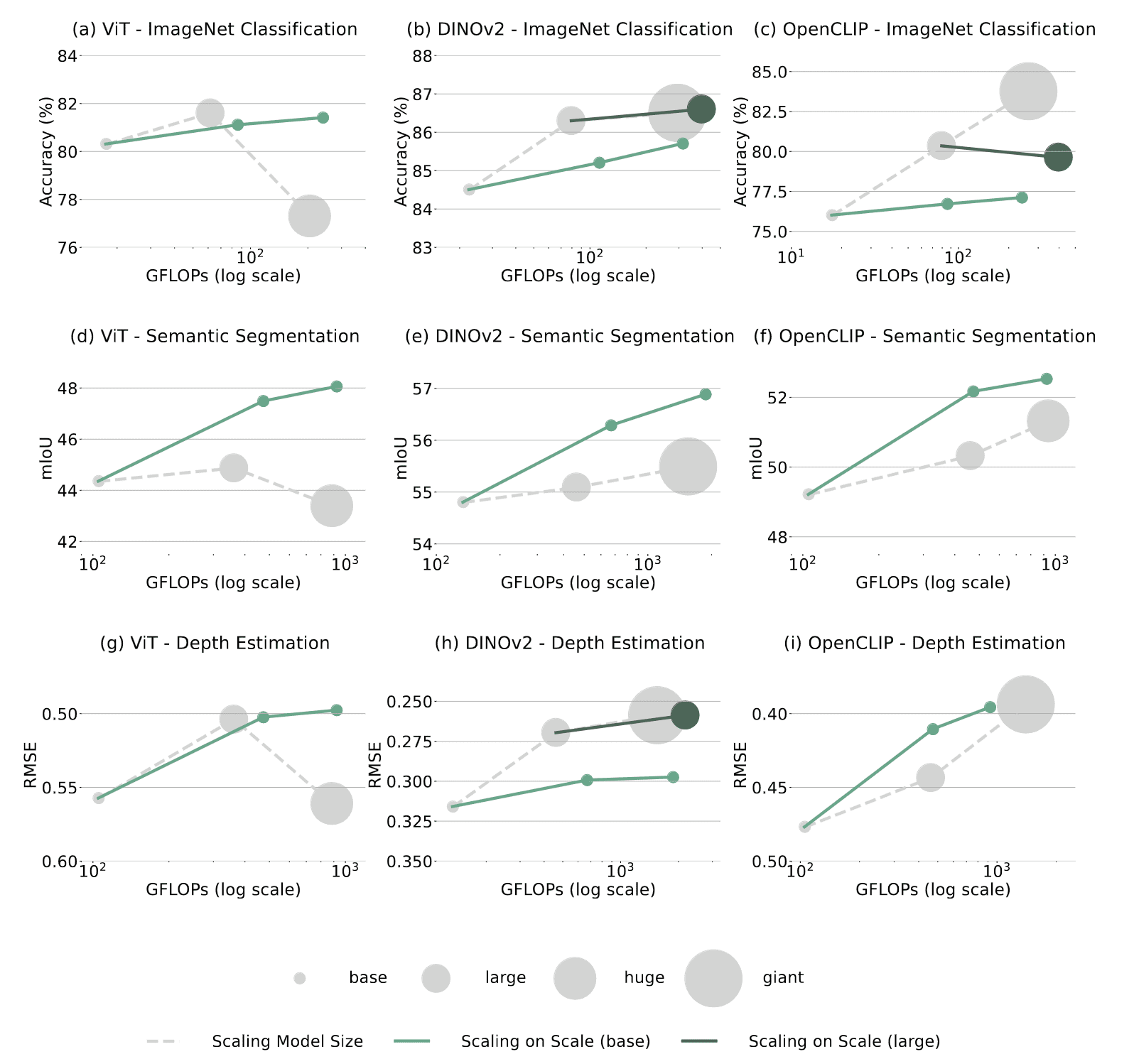
Superiority Beyond Model Size Scaling
On image classification, semantic segmentation, and depth estimation tasks, in most cases, S2 from base models gives a better scaling curve than model size scaling, outperforming large or giant models with similar GFLOPs and much fewer parameters.
- It has more advantages on dense prediction tasks such as segmentation and depth estimation;
- This matches the intuition that multi-scale features can offer better detailed understanding which is especially required by these tasks
- S2 is sometimes worse than model size scaling in image classification;
- Due to the weak generalizability of the base model feature
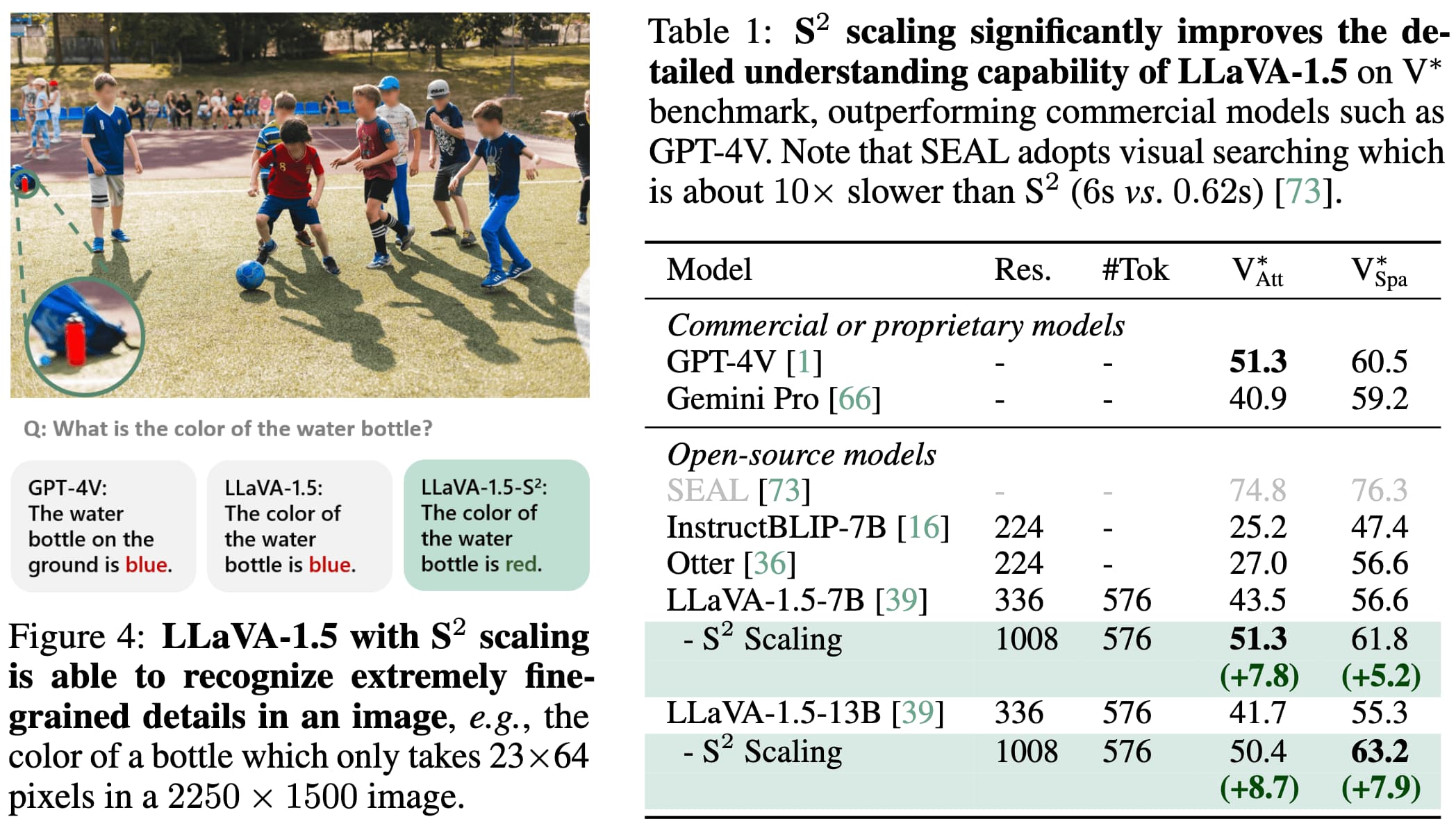
S2 is a preferable scaling approach for vision understanding in Multimodal LLMs as well. On all benchmarks, larger image scales consistently improve performance while bigger models sometimes fail to improve or even hurt performance.
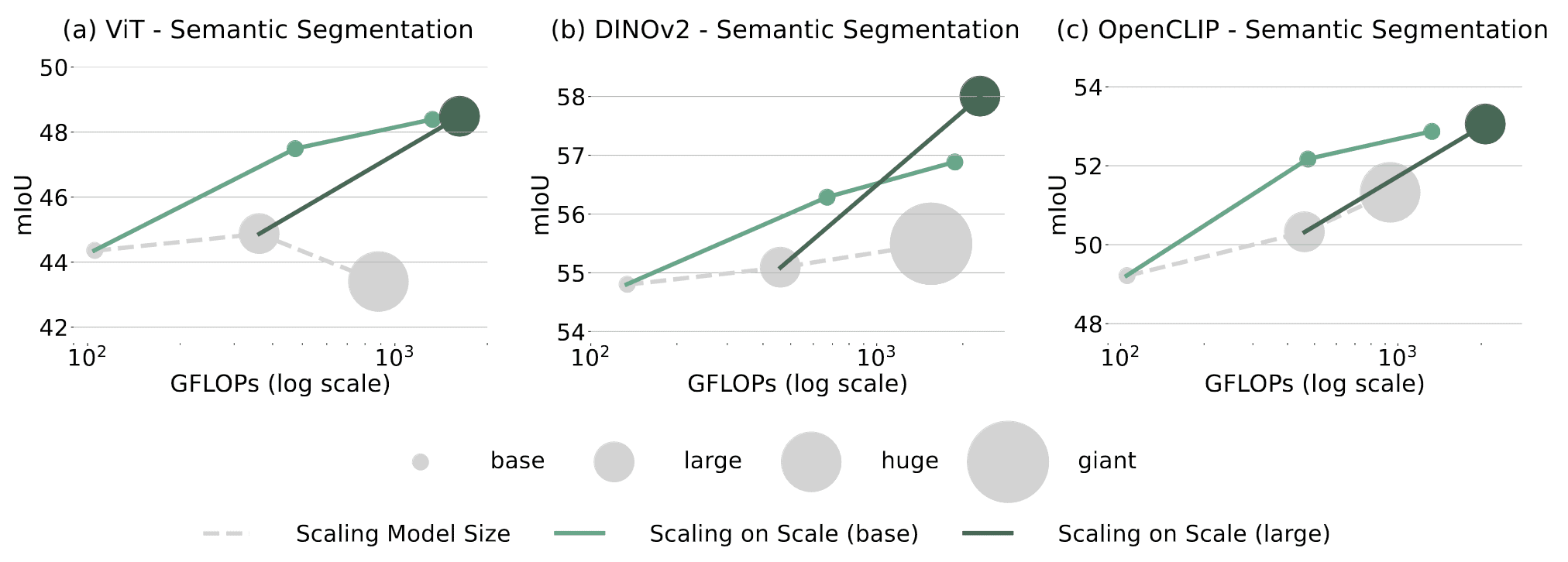
Sweet Spot Between Model Size Scaling and S2
The appropriate model size that synergizes with S2 varies for different pre-trained models.
- ViT, OpenCLIP: S2 from large models has no significant benefit than from base models
- DINOv2: S2 from large models beats S2 from base models
When Do We Not Need Larger Vision Models?
Although S2 demonstrates competitive performance in various downstream tasks, larger vision models still possess advantages, such as better generalization.
Better Generalizability of Larger Models
As an example, the authors explored two types of images in the image classification task where larger models have advantages:
- (a) Rare samples: larger models have greater capacity to learn to classify these rare examples during pre-training;
- (b) Ambiguous labels: despite multiple correct labels, the large model is able to remember the label presented in the dataset during pre-training;

Smaller Models Can Learn What Larger Models Learn
Then, when can smaller models with S2 achieve the same capability as larger models? They found that most features of larger models can be well approximated by features of multi-scale smaller models. For evaluation, they trained a linear transform to reconstruct the representation of a larger model from that of a multi-scale smaller model and utilized the following measurements:
- reconstruction loss $l$
-
the mutual information $I = - \log (l / l_0)$
- $l_0$ is the reconstruction loss when the large model representation is reconstructed by a dummy vector;
- quantify how much information in the larger model representation is also contained in the multi-scale smaller model;
-
ratio $r = I / I^*$
- $I^* = - \log (l^* / l_0)$
- $l^*$ is the reconstruction loss when the larger model representation is reconstructed by giant models;
- due to randomness in weight initialization and optimization dynamics, they observed that $l^*$ is never zero;
- therefore, $I^*$ serves as upper bound of $I$;
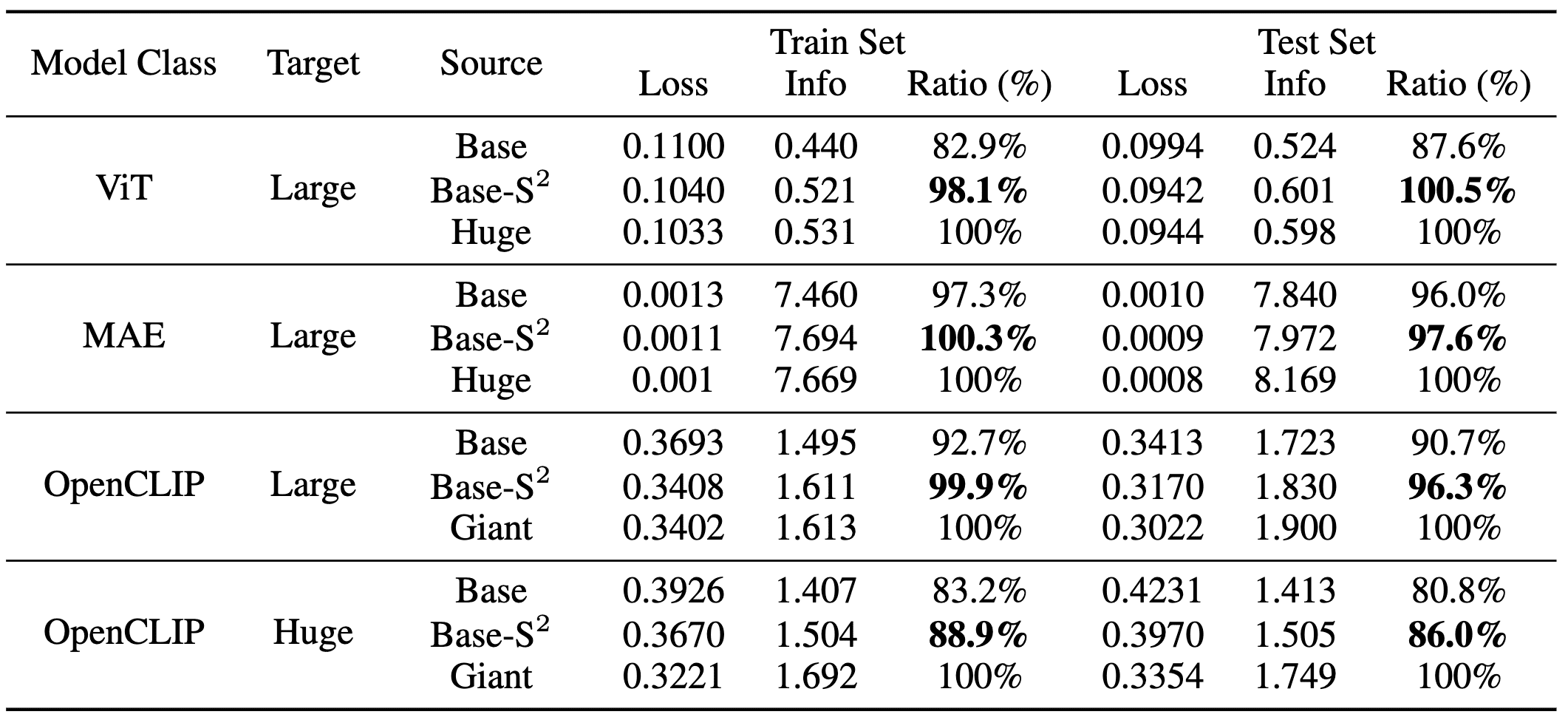
- Compared to base models, multi-scale base models consistently exhibit lower loss and reconstruct more information from the large model representation;
- In most cases, except for OpenCLIP-Huge features, the amount of information reconstructed from a multi-scale base model is usually close to that of a huge or giant model. Although sometimes slightly lower, it never falls short by a large margin;
Therefore, huge/giant models serve as a valid upper bound for feature reconstruction, and most part of the feature of larger models can also be learned by multi-scale smaller models. But smaller models with S2 should have at least a similar capacity to learn what larger models learn.
Pre-Training With S2 Makes Smaller Models Better
Given that multi-scale smaller models can learn most of the representations that larger models have, we can deduce that smaller models with S2 scaling have at least comparable capacity to larger models. The authors have demonstrated that multi-scale smaller models indeed exhibit similar capacity to larger models.
To quantify model capacity, they assessed the memorization capability by treating each image in the dataset as a separate category and training the model to classify individual images, which necessitates the model to memorize each image. Additionally, classification loss on the training set of ImageNet-1k for DINOv2 and OpenCLIP is also reported.
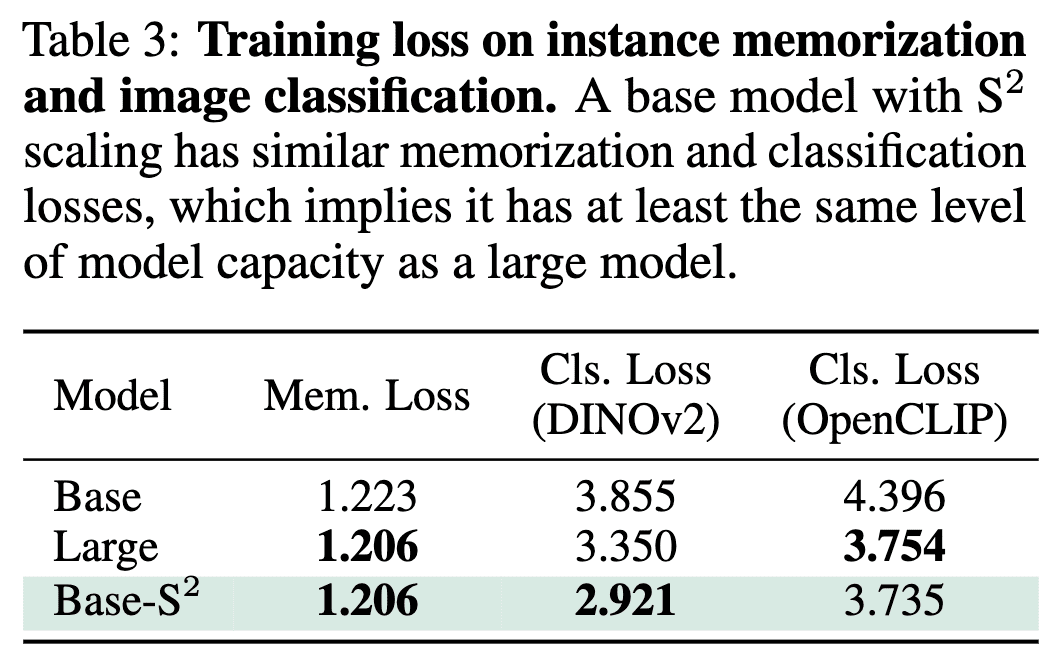
The results above indicate that multi-scale smaller models have comparable model capacity to larger models. Therefore, smaller models can achieve similar or even better generalizability than larger models if they are pre-trained with S2 scaling.
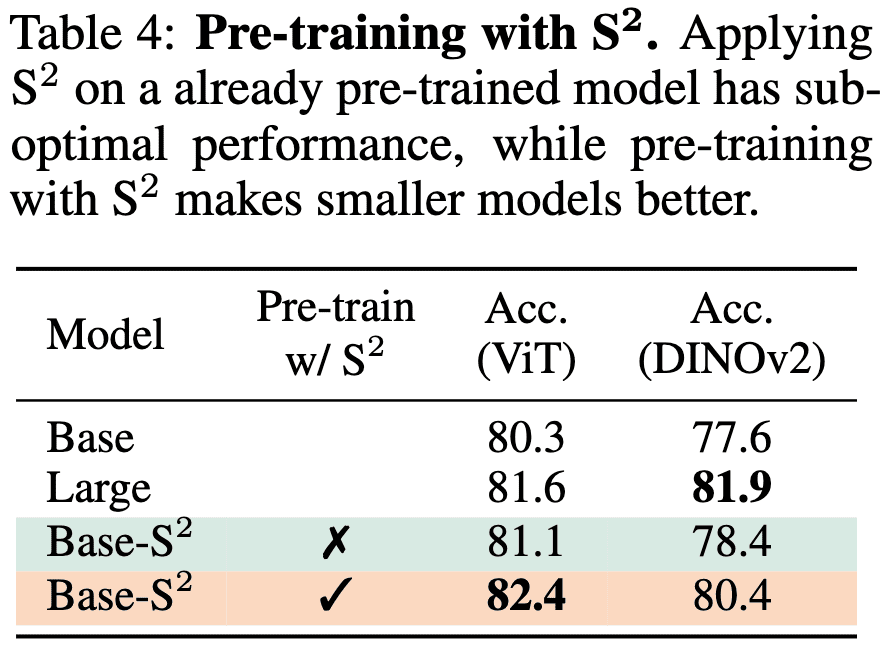
In the figure below, it is evident that when base models are trained with a single image scale and scaled to multiple image scales only after pre-training, their performance is suboptimal compared to larger models. However, with S2 during pre-training, the multi-scale base model can outperform the large model in the case of ViT. Similarly, in DINOv2, the base model pre-trained with S2 achieves significantly improved performance and approached the performance level of the larger model.
Reference
[1] Shi et al., “When Do We Not Need Larger Vision Models?” arXiv 2024
Leave a comment