
[DB] Intermediate SQL
Join Expressions
Instead of the Cartesian product, a number of join operations allow the programmer to write some queries in a more natural way and to express some queries that are difficult to do with only the Cartesian product.
Inner Join
The inner join returns only those rows that match/exist in both tables, i.e. do not preserve nonmatched tuples.
1
2
3
4
SELECT columns
FROM table1
INNER JOIN table2 /* or simply join depending on a DBMS */
ON table1.column = table2.column
The followings are equivalent:
1
2
3
4
5
6
7
8
9
10
/* Explicit: Preferred style */
SELECT employees.employee_id, employees.last_name, positions.title
FROM employees
INNER JOIN positions
ON employees.position_id = positions.position_id
/* Implicit: Old style (Not preferred) */
SELECT employees.employee_id, employees.last_name, positions.title
FROM employees, positions
WHERE employees.position_id = positions.position_id
Natural Join
The natural join operation operates on two relations and produces a relation as a result. It matches tuples with the same values for all common attributes, and retains only one copy of each common attribute.
1
r_1 NATURAL JOIN r_2 NATURAL JOIN ... NATURAL JOIN r_m
Unlike the Cartesian product of two relations, natural join considers only those pairs of tuples with the same value on those attributes that appear on the schema of both relations. It is an equi-join which occurs implicitly by comparing all the same name columns in both relations.
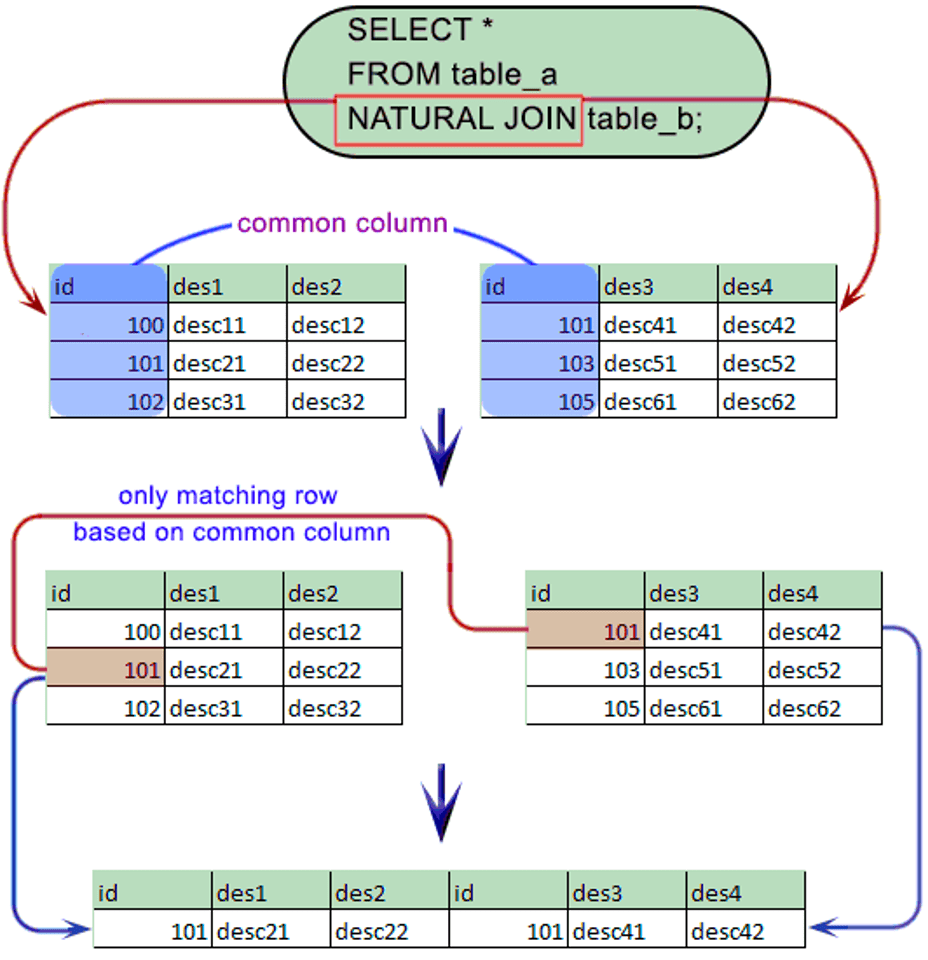
Hence, the followings are equivalent
1
2
3
4
5
6
7
--- Cartesian Product
SELECT name, course_id
FROM students, takes
WHERE student.ID = takes.ID
--- Natural Join
SELECT name, course_id
FROM students NATURAL JOIN takes;
It is a type of the equi-join which occurs implicitly by comparing all the same name columns in both tables.
Join conditions
To prevent equating attributes erroneously, SQL supports the specification of the join condition.
USING construct
The operation (INNER) JOIN ... USING requires a list of attribute names to be specified.
1
2
3
4
5
r_1 INNER JOIN r_2 USING(A_1, ... , A_n)
--- or (depends on DBMS)
r_1 JOIN r_2 USING(A_1, ... , A_n)
-
r_i: Relation -
A_i: Attribute
The operation is equivalent to:
1
2
3
4
5
6
SELECT *
FROM r_1,
r_2
WHERE COALESCE (r_1.A_1, r_2.A_1) AS A_1
AND ...
AND COALESCE (r_1.A_n, r_2.A_n) AS A_n
- e.g., List the names of students along with the titles of courses that they have taken
1
2
3
4
5
6
7
--- Without USING
SELECT name, title
FROM student NATURAL JOIN takes, course
WHERE takes.course_id = course.course_id;
--- With USING
SELECT name, title
FROM (student NATURAL JOIN takes) INNER JOIN course USING (course_id);
It is an equi-join; a special type of the inner join in which we use only an equality operator, and causes duplicate attributes to be removed from the result set.
ON construct
The ON condition allows a general predicate over the relaions being joined. This predicate is written like a WHERE clause predicate:
1
r_1 /* INNER */ JOIN r_2 ON p
-
r_i: Relation -
p: Predicate
hence the operation is equivalent to:
1
2
3
4
SELECT *
FROM r_1,
r_2
WHERE p
Therefore it becomes a theta join; a special type of the inner join in which arbitrary comparison relationships (such as $\geq$) are allowed, and it allows duplicate attributes to appear in the result set.
-
e.g., All attributes about all students, along with all the courses that they have took
1 2 3 4
SELECT * FROM student JOIN takes ON student.ID = takes.ID
Comparison of ON and USING
In a nutshell, ON can be used for most joins, but USING is a handy shorthand for the situation where the column names are the same. The following queries are equivalent.
1
2
3
4
5
6
7
8
9
10
11
--- Using ON
SELECT I.title, R.name
FROM albums I
INNER JOIN artists R
ON R.artist_id = I.artist_id;
--- Using USING
SELECT title, name
FROM albums
INNER JOIN artists
USING (artist_id);
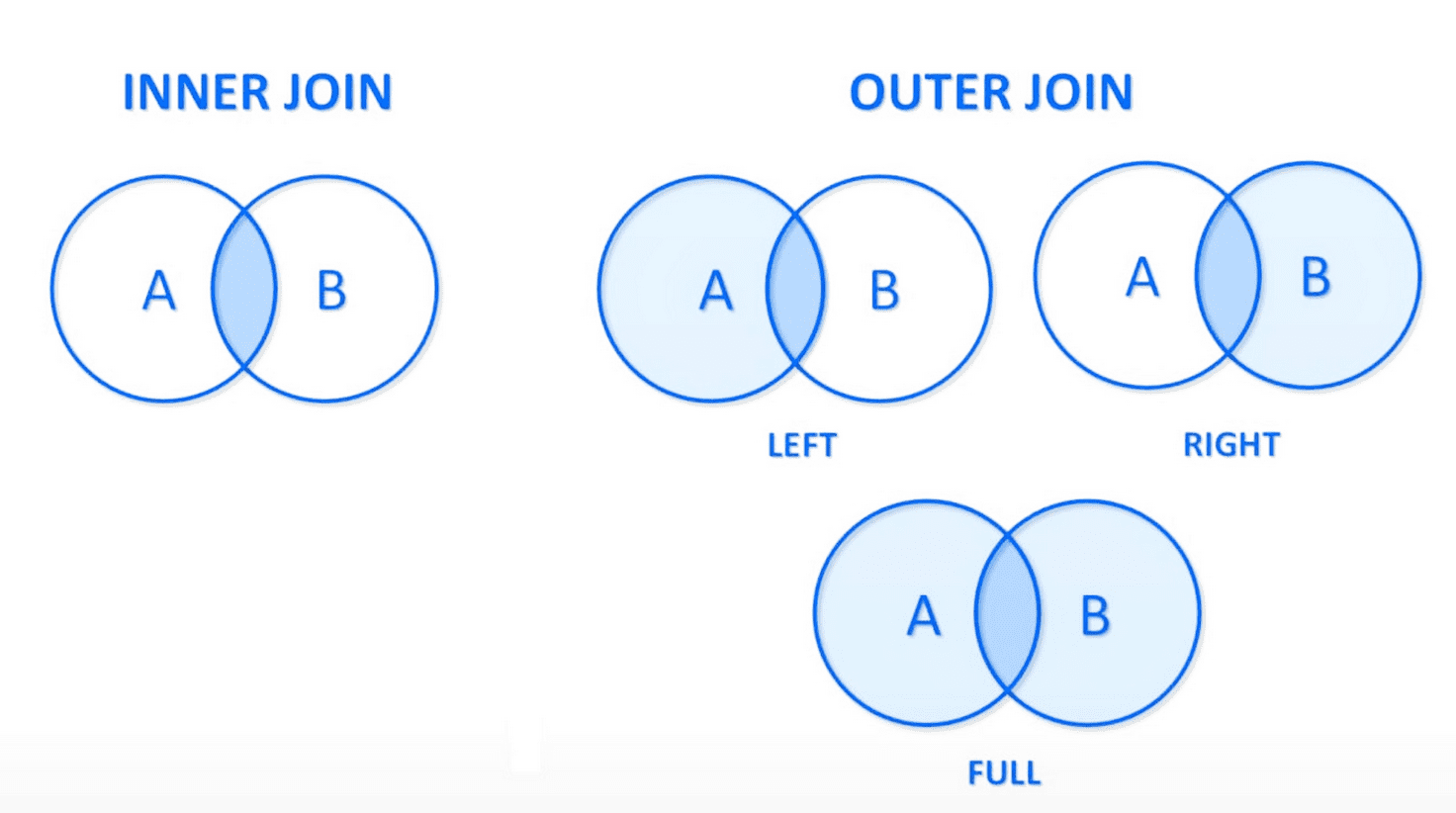
Outer Join
The outer join is an extension of the join operation that avoids loss of information. For example,
1
2
SELECT *
FROM student NATURAL JOIN takes
might exclude some student who takes no courses. The outer-join computes the join operation, and then adds tuples from one relation that does not match tuples in the other relation to the result of the join, using NULL values.
There are 3 forms of outer join:
-
LEFT OUTER JOIN
Preserves tuples only in the relation named to the left of theLEFT OUTER JOINoperation. -
RIGHT OUTER JOIN
Preserves tuples only in the relation named to the right of theRIGHT OUTER JOINoperation. -
FULL OUTER JOIN
Preserves tuples in both relations.
In constrast, the join operations that do not preserve nonmatched tuples are called INNER JOIN operations.
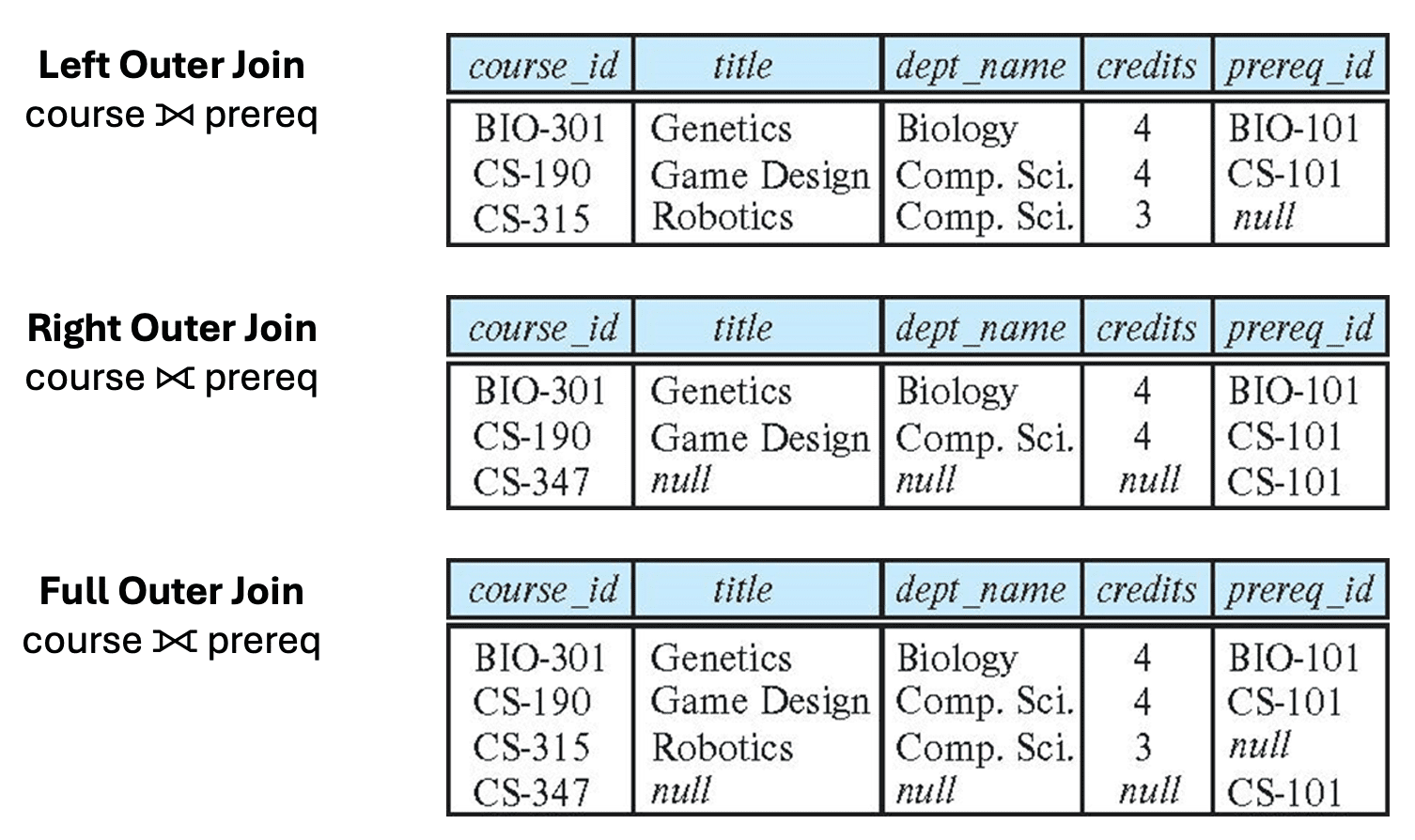
Join Condition for Outer Join
-
table1 NATURAL [LEFT | RIGHT | FULL] OUTER JOIN table2-
e.g., Find all students who have not taken a course
1 2 3
SELECT ID FROM student NATURAL LEFT OUTER JOIN takes WHERE course_id is NULL;
-
table1 NATURAL [LEFT | RIGHT | FULL] OUTER JOIN table2 ON ptable1 NATURAL [LEFT | RIGHT | FULL] OUTER JOIN table2 USING (A_1, ..., A_n)
Example.
Suppose that the relation student has a tuple with name Snow, which has no corresponding tuples in the takes relation. The following two queries are not equivalent.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
SELECT *
FROM student
LEFT OUTER JOIN takes
ON student.ID = takes.ID;
WHERE student.name = 'Snow'
-- Result: (70557, 'Snow', 'Physics', 0, NULL, NULL, NULL, NULL, NULL, NULL)
--- NOT EQUIVALENT
SELECT *
FROM student
LEFT OUTER JOIN takes
/* ON student.ID = takes.ID; */
WHERE student.ID = takes.ID
AND student.name = 'Snow'
-- Result: (empty)
In the latter query, every tuple satisfies the join condition vacuously, hence the outer join actually generates the Cartesian product of the two relations. Since there are no tuples in takes with the ID '70557', every time a tuple appears in the outer join with the name 'Snow', the values for student.ID and takes.ID must be different, and such tuples are eliminated by the WHERE clause predicate. Thus the resultset is empty.
Views
In some cases, it is not desirable for all users to see the entire logical model (i.e., all the actual relations stored in the database). For example, consider a person who needs to know an instructor name and his/her department, but not his/her salary; this person should see a relation described in SQL:
1
2
SELECT ID, name, dept_name
FROM instructor
Aside from security concerns, one may wish to create personalized collection of relations that is better matched to a certain user’s intuition than is the logical model. In SQL, a view provides a mechanism to hide certain data from the view of certain users.
SQL allows a virtual relation to be defined by a query, and the relation conceptually contains the result of the query. Any such relation that is not part of the logical model, but is made visible to a user as a virtual relation, is called a view.
View Definition
A view is defined using the CREATE VIEW.
1
CREATE VIEW v AS Q
-
v: The name of the view -
Q: Any legal SQL expression
Once a view is defined, the view name can be used to refer to the virtual relation that the view generates.
View denition is not the same as creating a new relation by evaluating the query expression. Rather, a view definition causes the saving of an expression; the expression is substituted into queries that is using the view, which is called query modification. Also views differ from the WITH statement in that views, once created, remain available until explicitly dropped. The named subquery defined by WITH is local to the query in which it is defined.
- e.g., A view of instructors without their salary and find all instructors in the Biology department
1
2
3
4
5
6
7
8
9
10
CREATE VIEW faculty AS
SELECT ID,
name,
dept_name
FROM instructor;
SELECT name
FROM faculty
-- Views can be used like relations
WHERE dept_name = 'Biology';
- e.g., A view of department salary totals
1
2
3
4
5
CREATE VIEW
dept_total_salary (dept_name, total_salary) AS
SELECT dept_name, SUM(salary)
FROM instructor
GROUP BY dept_name;
Views Expansion (View Defined Using Other Views)
A view can be used in the expression defining another view.
-
Direct dependency
A view relation $v_1$ is said to depend directly on a view relation $v_2$, if $v_2$ is used in the expression defining $v_1$. -
Dependency
A view relation $v_1$ is said to depend on a view relation $v_2$, if either $v_1$ depends directly to $v_2$, or there exists a path of dependencies from $v_1$ to $v_2$. -
Recursion
A view relation $v$ is said to be recursive if it depends on itself.
And view expansion is a way to define the meaning of views defined in terms of other views. Suppose that a view $v_1$ is defined by an expression $e_1$ that may itself contain uses of view relations. It follows the following replacement step:
1
2
3
4
REPEAT
Find any view relation v_i in e_1
Replace the view relation v_i by the expression defining v_i
UNTIL nomore view relation are present in e_1
As long as the view definitions are not recursive, the loop will terminate eventually.
Example
1
2
3
4
5
6
7
8
9
10
11
CREATE VIEW physics_fall_2017 AS
SELECT course.course_id, sec_id, building, room_number
FROM course, section
WHERE course.course_id = section.course_id
AND course.dept_name = 'Physics'
AND section.semester = 'Fall'
AND section.year = 2017;
CREATE VIEW physics_fall_2017_watson AS
SELECT course_id, room_number
FROM physics_fall_2017
WHERE building= 'Watson';
Materialized Views
Certain database systems allow view relations to be physically stored, that is, a physical copy of the ‘virtual’ relation created when the view is defined. Such views are called materialized views. It is especially efficient for views that are very commonly used.
If relations used in the query are updated, the materialised view reult becomes out-of-date; views must be maintained to date by updating the view whenever the underlying relations are updated.
For example, consider the view departments_total_salary. If that view is materialized, its results would be stored in the database, allowing queries that use the view to potentially run much faster by using the precomputed view result, instead of recomputing it.
However, if an instructor tuple is added to or deleted from the instructor relation, the result of the query defining the view would change, and as a result the materialized view’s contents must be updated. Similarly, if an instructor’s salary is updated, the tuple in departments_total_salary corresponding to that instructor’s department must be updated.
Update of View
Although views are a useful tool for queries, they present serious problems when undergoing updates, insertions, or deletions.
- Missing Attribute
-
e.g., Add a new tuple to the view faculty defined earlier
1 2
INSERT INTO faculty VALUES ('30765', 'Green', 'Music');
-
This insertion must be represented by the insertion into the instructor relation, which must have a salary attribute that is inaccessible. There are two reasonable approaches to dealing with this insertion:
- Reject the insertion.
- Insert a tuple with the value of the non-existing attribute set to
NULL.- But will be rejected by the DBMS if that attribute has
NOT NULLconstraint.
- But will be rejected by the DBMS if that attribute has
- Ambiguity
Another issue with modification of the database through views is that some updates cannot be translated uniquely.
-
Example
1 2 3 4 5 6
CREATE VIEW instructor_info AS SELECT ID, name, building FROM instructor, department WHERE instructor.dept_name = department.dept_name INSERT INTO instructor_info VALUES ('69987', 'White', 'Taylor');
-
Issues
- Which department, if multiple departments in Taylor?
- What if no department is in Taylor?
- There is no way to update the relations
instructoranddepartmentby usingNULLvalues to get the desired update on the viewinstructor_info.
-
Issues
-
Example
1 2 3 4 5 6
CREATE VIEW history_instructors AS SELECT * FROM instructor WHERE dept_name = 'History' INSERT INTO history_instructors VALUES ('25566', 'Brown', 'Biology', 7000);
-
Issues
- Should the insertion be allowed?
- This tuple can be inserted into the
instructorrelation following the rules below, but it would not appear in thehistory_instructorsview since it does not satisfy the selection imposed by the view.
- This tuple can be inserted into the
- Should the insertion be allowed?
-
Issues
Because of problems such as these, modifications are generally not permitted on view relations, except in limited cases. Different database systems specify different conditions under which they permit updates on view relations.
And in general, most SQL implementations allow updates only on simple views:
- The
FROMclause has only one database relation. - The
SELECTclause contains only attributes of the relation, and does not have any expression, aggregates, or DISTINCT specification. - Any attribute not listed in the
SELECTclause can be set toNULL. - The query does not have a
GROUP BYorHAVINGclause.
Transactions
- A transaction consists of a sequence of query and/or update statements. It is a unit of work.
- The SQL standard specifies that a transaction begins implicitly when an SQL statement is executed.
- The transaction must end with one of the following statements:
- Commit work The updates performed by the transaction become permanent in the database; cannot be undone by rollback work;
- Rollback work All the updates performed by the SQL statements in the transaction are undone;
- The database provides an abstraction of a transaction as being atomic, that is, indivisible. Either all the effects of the transaction are reflected in the database, or none are (after rollback).
Integrity Constraints
Integrity constraints ensure that changes made to the database by authorised users do not result in a loss of data consistency. Thus, integrity constraints guard against accidental damage to the database.
There are some integrity-constraint statements allowed to be included in the CREATE TABLE command:
NOT NULLPRIMARY KEYUNIQUECHECK(<predicate>)
NOT NULL constraint
- The
NULLvalue is a member of all domains, hence is a legal value for every attributie in SQL by default. - However, for certain attributes,
NULLvalues may be inappropriate. -
The
NOT NULLspecification is an example of domain constraint that prohibits the insertion of aNULLvalue for the attribute.1
A D NOT NULL
-
A: Attribute -
D: Domain
-
UNIQUE constraint
-
THe
UNIQUEspecification states that the attributes specified form a candidate key.1
UNIQUE (A_1, ..., A_n)
-
A_i: Attributes
-
- Attributes $(A_1, \cdots, A_n)$ form a candidate key; that is, no two tuples can be equal on all the listed attributes.
- Candidates keys are permitted to be
NULL(unless explicitly declared to beNOT NULL), in contrast to primary keys.
CHECK clause
- The
CHECKclause specifies a predicatePthat must be satisfied by every tuple in a relation.-
e.g., Ensure that
semesteris one of ‘Autumn’, ‘Winter’, ‘Spring’, or ‘Summer’1 2 3 4 5 6 7
CREATE TABLE section ( ... semester VARCHAR(6), ... CHECK(semester IN ('Autumn', 'Winter', 'Spring', 'Summer')) )
-
-
The predicate in the
CHECKclause can be an arbitrary predicate that can include a subquery (but jot supported in SQLite3).1 2 3 4 5 6 7 8
CHECK ( time_slot_id IN ( SELECT time_slot_id FROM time_slot ) )
- The condition must be checked not only when a tuple is inserted or modified in
section, but also when the relationtime_slotchanges.
- The condition must be checked not only when a tuple is inserted or modified in
-
CHECKclause is satisfied if it is not false, so clauses that evalutate toUNKNOWNare not violations.
Referential Integrity
- Referential integrity ensures that a value that appears in one relation (referencing relation) for a given set of attributes also appears for a certain set of attributes in another relation (referenced relation).
- By default, a foreign key references the primary key attributes of the referenced table. Non-primary keys can also be referenced by foreign keys, but the attribute must have
UNIQUEconstraint specified. -
SQL allows a list of attributes of the referenced relation to be specified explicitly:
1
FOREIGN KEY(A_1, ... , A_k) REFERENCES r(B_1, ... , B_k)
-
A_i,B_i: Attributes -
r: Reference relation
-
Cascading Actions
- When a referential integrity constraint is violated, the normal procedure is to reject the action that caused the violation. An alternative in case of
DELETEorUPDATEis to cascade actions. -
CASCADEspecification ensures that whenever a referenced key is deleted or updated (depending on the specification), the same operation is cascaded to all the referencing keys.1 2 3 4 5 6 7 8
CREATE TABLE course ( ... dept_name VARCHAR(20), FOREIGN KEY (dept_name) REFERENCES department ON DELETE CASCADE ON UPDATE CASCADE );
- If a
DELETEof a tuple indepartmentresults in this reference integrity constraint being violated, theDELETEoperation cascades to thecourserelation, deleting the tuple that refers to the department that was deleted. Similar process also happens forUPDATE.
- If a
- The followings can be used instead of
CASCADE:-
SET NULL
Whenever a tuple of referenced key relation is removed, set the value of all tuples of the referencing key with the same value toNULL. -
SET DEFAULT
Same as above, but use default value instead ofNULL. -
NO ACTION
No action is done; referential integrity is violated. -
RESTRICT
An error is return.
-
Integrity Constraint Violation During a Transaction
- Integrity constraints may be violated temporarily during transactions.
-
e.g., John and Mary are married to each other by inserting two tuples, one for John and one for Mary, in the preceding relation, with the spouse attributes set to Mary and John, respectively. But, the insertion of the first tuple would violate the foreign-key constrain
1 2 3 4 5 6 7 8
CREATE TABLE person ( ID CHAR(10), name VARCHAR(40), spouse CHAR(10), PRIMARY KEY (ID), FOREIGN KEY (spouse) REFERENCES person );
-
How can a tuple be inserted without causing constraint violation? There are some ways to do this:
- Insert
fatherandmotherof a person before inserting that person - Set
fatherandmothertoNULLinitially, and update after inserting all persons- Not possible if father and mother attributes are declared to be
NOT NULL
- Not possible if father and mother attributes are declared to be
- Defer constraint checking until the end of the transaction
-
INITIALLY DEFERREDclause
-
Assertions
- An assertion is a predicate expressing a condition that we wish the database always to satisfy
- An assertion in SQL takes the form:
-
create assertion <assertion-name> check (<predicate>);
-
- Example
-
For each tuple in the student relation, the value of the tot_cred attribute must equal to the sum of credits of the courses that the student has completed successfully
1 2 3 4 5 6 7
CREATE ASSERTION credits_earned_constraint CHECK (NOT EXISTS (SELECT ID FROM student WHERE tot_cred <> (SELECT COALESCE (SUM (credits), 0) FROM takes NATURAL JOIN course WHERE student.ID = takes.ID AND grade IS NOT NULL and grade <> 'F')))
-
An instructor cannot teach in two different classrooms in a semester in the same time slot
-
- Not supported in SQLite3
SQL Data Types and Schemas
In addition to the basic data types, the SQL standard supports several data types.
Built-in Data Types in SQL
-
DATE- Dates in
YYYY-MM-DDformat - e.g.
DATE '2005-07-27'
- Dates in
-
TIME- Time of day in hours, minutes, and seconds
- e.g.
TIME '09:00:30',TIME '09:00:30.75'
-
TIMESTAMP- DATE + TIME
- e.g.
TIMESTAMP '2001-11-15 09:00:30.75'
SQL alloows comparison operations on all the types listed above. SQL also allows computations based on dates and times and on intervals:
-
INTERVALINTERVAL <value> <unit>- e.g.
INTERVAL '1' day - Subtracting a
DATE/TIME/TIMESTAMPfrom another gives anINTERVALvalue
CAST, COALESCE, DEFAULT
-
We can use an expression of the following form to convert an expression
eto the typet:1
CAST (e AS t)
-
We can choose how
NULLvalues are output in a query result using theCOALESCEfunction:1 2
SELECT ID, COALESCE (salary, 0) AS salary FROM instructor
-
SQL allows a
DEFAULTvalue to be specified for an attribute:1 2 3 4 5 6
CREATE TABLE STUDENT (ID VARCHAR (5), name VARCHAR (20) NOT NULL, dept_name VARCHAR (20), tot_cred NUMERIC (3,0) DEFAULT 0, PRIMARY KEY (ID));
Large-Object Types
- Many current-generation database applications need to store attributes that can be large.
- Large objects (photos, videos, CAD files, etc.) are stored as a large object:
-
BLOB: binary large object- an object is a large collection of uninterpreted binary data (whose interpretation is left to an application outside of the database system)
-
CLOB: character large object- an object is a large collection of character data
-
- When a query returns a large object, a pointer is returned rather than the large object itself
User-Defined Types
-
SQL provides the notion of distinct types. The
CREATE TYPEclause can be used to define new types.1
CREATE TYPE new_t AS pre_t FINAL;
-
new_t: Name of the new type -
pre_t: Pre-existing type - Use the
[NOT] FINALclause to indicate whether any further subtypes can be created for this type.- (Default) Specify
FINALif no further subtypes can be created for this type. - Specify
NOT FINALif further subtypes can be created under this type.
- (Default) Specify
-
e.g. comparing the
Dollarvalue andPoundvalue is not valid1 2
CREATE TYPE Dollars AS NUMERIC (12, 2) FINAL; CREATE TYPE Pounds AS NUMERIC (12, 2) FINAL;
- Then, an attempt to assign a value of type
Dollarsto a variable of typePoundsresults in a compile-time error
-
- SQL provides
DROP TYPEandALTER TYPEclauses to drop or modify types that have been created earlier. -
Before user-defined types were added to SQL, SQL had similar but subtly different notion of domain, which can add integrity constraints to an underlying type. (Not supported in SQLite3)
1 2
CREATE DOMAIN new_d pre_t CONSTRAINT ...
-
new_d: Name of the new domain -
pre_t: Pre-existing type -
e.g.
1
CREATE DOMAIN Dollars AS NUMERIC (12, 2) NOT NULL;
-
e.g.
1 2
CREATE DOMAIN YearlySalary NUMERIC (8, 2) CONSTRAINT salary_value_test CHECK (VALUE >= 29000.00);
-
- There are two significant differences between types and domains:
- Domains can have constraints specified on them, and can have default values defined for variables of the domain type, whereas user defined types cannot have constraints of default values specified on them.
- Domains are not strongly typed; values of one domain can be assigned to values of another domain as long as the underlying types are compatible.
Index Creation
- Many queries reference only a small proportion of the records in a table. Thus, it is inefficient for the system to read every record to find a record with particular value.
-
An index on an attribute of a relation is a data structure that allows the database system to find those tuples in the relation that have a specified value for that efficiently, without scanning through all the tuples of the relation.
1
CREATE INDEX i ON r(A_1, ..., A_k)
-
i: Name of the index -
r: Relation -
A_i: Attributes
-
-
For example,
1 2 3 4 5
CREATE INDEX studentID_idx ON student(ID); SELECT * FROM student WHERE ID = '12345'
- The above query can be executed by using the index to find the required record, without looking at all records of student.
Authorization
A user can be assigned several forms of authorisations on parts of the database:
- Read: Allows reading, but not modification of data
- Insert: Allows insertion of new data, but not modification of existing data
- Update: Allows modification, but not deletion of data
- Delete: Allows deletion of data
Each of these types of authorisations is called privilege.
A user can be authorised all, none, or a combination of these types of privileges on specified parts of a database, such as a relation or a view.
GRANT statement
-
The
GRANTstatement is used to confer authorization.1 2 3
GRANT <privilege list> ON <reltation/view> TO <user/role list>;
- Here,
<privilege list>can be-
SELECT: Allows read access, or the ability query using the view -
INSERT: Ability to insert tuples -
UPDATE: Ability to update using the SQLUPDATEstatement -
DELETE: Ability to delete tuples -
ALL PRIVILEGES: Short form for all the allowable privileges
-
- The
<user list>can be- user ID
-
PUBLIC, which allows all valid users the privilege granted - role (we cover this concept in the next section)
-
For example,
1 2
GRANT SELECT ON department TO Amit, Satoshi GRANT UPDATE (budget) ON department TO Amit, Satoshi
- Note that
- Granting a privilege on a view does not imply granting any privileges on the underlying relations.
- The grantor of the privilege must already hold the privilege on the specified item.
REVOKE statement
-
The
REVOKEstatement is used to revoke authorization.1 2 3
REVOKE <privilege list> ON <reltation / view> TO <user list>;
- the
<privilege list>may beALL: ALL privileges the revokee may hold, are revoked. - If the
<user list>isPUBLIC: ALL users lose the privilege, except those granted it explicitly.
- the
-
For example,
1 2
REVOKE SELECT ON department TO Amit, Satoshi REVOKE UPDATE (budget) ON department TO Amit, Satoshi
-
Note that
- If the same privilege was granted more than once to the same user by different grantors, then the user may retain the privilege after one revocation.
- All privileges that depend on the privilege being revoked are also revoked.
- e.g., in some DBMSs (not all DBMSs), the select privilege is required for the insert, update, and delete privileges
Roles
- A role is a way to distinguish among various users as far as what these users can access / update in the database.
- e.g., each instructor must have the same types of authorizations on the same set of relations. Whenever a new instructor is appointed, she will have to be given all these authorizations individually.
- A role can be thought of as a set of privileges; with roles, privileges of multiple users can be managed at once.
-
Roles can be created as following:
1
CREATE ROLE <name>
-
Once a role is created, users can be assigned to the role as following.
1 2
GRANT <role> TO <user list>
-
-
For example,
1 2 3 4 5 6 7 8
CREATE ROLE instructor GRANT SELECT ON takes TO instructor CREATE ROLE dean GRANT instructor TO dean; GRANT dean TO Satoshi;
- Note that
- Privileges can be granted to roles.
- Roles can be granted to users, as well as to other roles.
- Thus, there can be a chain of roles
- e.g.
teaching_assistant$\to$instructor$\to$dean
- e.g.
Authorization on Views
- A user who creates a view must have at least
SELECTprivilege on the base relation. - The creator of the view does not receive all privileges on that view.
- Obviously, only those privileges that provide no additional authorization beyond those that the user already had, are given.
- e.g., a user who creates a view can’t be given
UPDATEauthorization on a view without havingUPDATEauthorization on the relations used to define the view.
- Users who received only the privilege on the view does not have privilege on the base relation.
-
For example
1 2 3 4 5 6 7 8 9 10
/* The creator of a view should have the select privilege on the base relation */ CREATE VIEW geo_instructor AS (SELECT * FROM instructor WHERE dept_name = 'Geology'); GRANT SELECT ON geo_instructor TO geo_staff; /* The staff member (geo_staff) is authorized to see the result of this query */ SELECT * FROM geo_instructor;
REFERENCES Privilege
-
SQL includes a
REFERENCESprivilege that permits a user to declare foreign keys when creating relations.1 2 3
GRANT REFERENCES(A_1, ... , A_k) ON r TO <user list>;
-
r: Relation -
A_i: Attributes ofr
-
-
Such privilege is required because
- Foreign key constraints restrict deletion and update operations on the referenced relation, which may restrict future activity by other users.
- With the
REFERENCESprivilege, the user can check for the existence of a certain value in a certain (set of) attributes of the referenced relation.
Transfer of Privileges
- By default, a user/role that is granted a privilege is not authorized to grant that privilege to another user/role
-
Add
WITH GRANT OPTIONclause to grant the privilege to allow the recipient to pass the privilege onto other users can be explicitly given.1 2 3 4
GRANT <privilege list> ON <relation / view> TO <user list> WITH GRANT OPTION;
- The passing of a specific authorization from one user to another can be represented by an authorization graph.
- A user has an authorization if and only if there is a path from the root of the authorization graph down to the node representing the user.
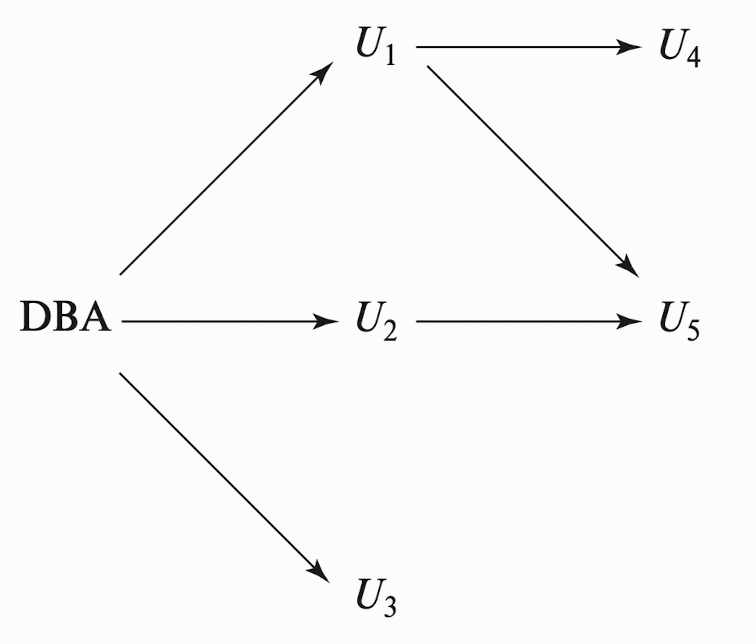
- A pair of devious users might attempt to defeat the rules for revocation of authorization by granting authorization to each other.
- e.g. $U_2$ grants his/her privileges to $U_3$. When DBA revokes $U_2$’s grant, $U_2$ might retains authorization $U_3$.
- Thus, SQL ensures that the authorization is revoked from both the users.
- Revocation of a privilege from a user/role may cause other users/roles also to lose that privilege
- Cascading revocation is also inappropriate in many situations.
- e.g. Satoshi has the role of
dean, grantsinstructorto Amit. When the roledeanis revoked from Satoshi later; Amit continues to be employed on the faculty and should retain theinstructorrole.
- It is also possible to specify the actions when a privilege is revoked from a user.
-
One option is to cascade the revoking operation: all privileges the revokee granted with
GRANT OPTIONis also revoked.1 2 3 4
REVOKE <privilege list> ON <relation / view> FROM <user list> CASCADE;
- The keyword
CASCADEcan be omitted, as it is the basic behavior of theREVOKEoperation.
- The keyword
-
Another option is to restrict cascading revocation; returning an error if cascading revocation is required.
1 2 3 4
REVOKE <privilege list> ON <relation / view> FROM <user list> RESTRICT;
-
Reference
[1] Silberschatz, Abraham, Henry F. Korth, and Shashank Sudarshan. “Database system concepts.” (2011).
Leave a comment