
[DB] Big Data
Traditional applications of relational databases are based on structured data, and typically manage data from a single enterprise. Modern data management applications, however, often need to handle data that is not necessarily in relational form. Moreover, these applications must manage volumes of data far exceeding what a single enterprise would generate. In this post, we explore techniques for managing such data, commonly referred to as Big Data.
Motivation
The growth of the Web, social media, and more recently Internet-of-Things resulted in the need to store and query large volumes of data that far exceeded the enterprise data that relational databases were designed to manage. Such data, are characterized by their size, speed at which they are generated, and the variety of formats, are generically called Big Data.
Big Data is differentiated from data handled by earlier generation databases by the following metrics:
- Volume: much larger amounts of data stored;
- Velocity: much higher rates of insertions; e.g., streaming
- Variety: many types of data, beyond relational data;
While SQL is the most widely used language for querying relational databases. However, there is a wider variety of query language options for Big Data applications, driven by the need to handle more variety of data types, and by the need to scale to very large data volumes/velocity.
-
Transaction-processing systems that need very high scalability
- Many applications are willing to sacrifice ACID properties and other database features, if they can get very high scalability
- ACID: Atomicity, Consistency, Isolation, Durability
- Query-processing systems that need very high scalability and support for non-relational data
Big Data Storage Systems
A number of systems for Big Data storage have been developed and deployed over the past two decades to address the data management requirements of such applications.
- Distributed file systems
- Key-value storage systems
- Parallel and distributed databases
Distributed File Systems
A distributed file system stores data across a large collection of machines, but provides a single file-system view. It provides abundant storage of massive amounts of data on cheap and unreliable computers Files are replicated to handle hardware failure ?
A landmark system is Hadoop File System (HDFS).
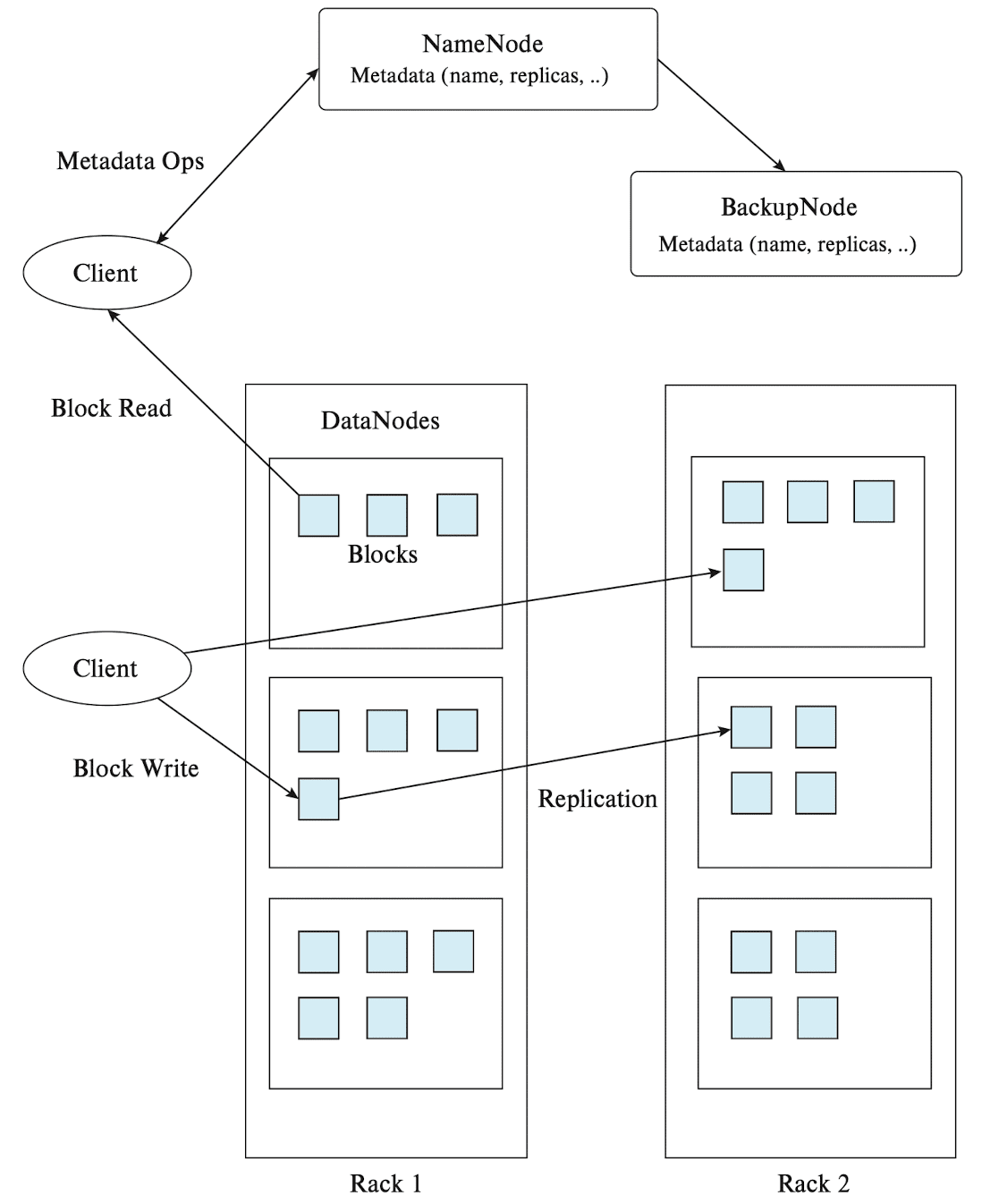
The core of HDFS is a server running a machine referred to as the NameNode. All file system requests are sent to the NameNode. Files are broken up into blocks (typically a size of 64 MB), and each block is replicated on multiple DataNodes, mapping a block identifier to a physical location on disk. Since NameNode maps a filename to a list of block identifiers and each block identifier to DataNodes containing a replica of the block, a client access a file by:
(1) Finding the locations of blocks from NameNode
(2) Accessing the data directly from DataNode
Note that such systems are suitable for large files but not for a large number of small files. Key-Value storage systems can effectively benchmark this scenario.
Key-Value Storage Systems
A key-value storage system provides a way to store large numbers (billions or even more) of small (KB ~ MB) sized records (value) with an associated key and to retrieve the record with a given key. Key-value stores may store
-
Uninterpreted bytes, with an associated key
- e.g., Amazon S3, Amazon Dynamo
-
Wide-table (can have arbitrarily many attribute names) with an associated key
- Google BigTable, Apache Cassandra, Apache Hbase, Amazon DynamoDB
- Allows some operations (e.g., filtering) to execute on storage node
- Several such key-value storage systems require the stored data to follow a specified data representation, allowing the data store to interpret the stored values and execute simple queries based on stored values.
- Such data stores are called document stores.
- Typically, JSON
- MongoDB, CouchDB (document model)
An important motivation for the use of key-value stores is their ability to handle very large amounts of data as well as queries, by distributing the work across a cluster consisting of a large number of machines. To support distribution, records are partitioned across multiple machines and queries are routed by the system to appropriate machine. Records are also replicated across multiple machines, to ensure availability even if a machine fails. And Key-value systems ensure that updates are applied to all replicas, to ensure that their values are consistent.
As the name implies, key-value storage systems are based on two primitive functions:
-
put(key, value): stores values with an associated key- Document stores also support queries on non-key attributes
-
get(key): retrieves the stored value associated with the specified key
Note that Key-value stores are not full database systems. For instance, transactional updates are not supported or limited, and do not support declarative querying; applications must manage query processing on their own. (Key-value stores are also called NoSQL systems, to emphasize that they do not support SQL.)
An important reason for not supporting such features is that they are challenging to implement on very large clusters. Consequently, most systems sacrifice these features to achieve scalability.
Parallel and Distributed Databases
Parallel databases are databases that run on multiple machines (together referred to as a cluster) and are designed to store data across multiple machines and to process large queries using multiple machines. Parallel databases were initially developed in the 1980s, well before Big Data.
However, when such database systems operate on clusters with thousands of machines, the probability of failure during the execution of a query increases significantly, especially for queries that process large amounts of data and consequently run for extended periods. Restarting a query in the event of a failure is no longer a viable option, as there is a considerable likelihood that another failure will occur during the query’s execution. Techniques to avoid a complete restart, allowing only the computation on the failed machines to be redone, were developed in the context of map-reduce systems.
Replication and Consistency
So far, we observed that replication is key to ensuring availability of data, ensuring a data item can be accessed despite failure of some of the machines storing the data item. Any update to a data item must be applied to all replicas of the data item.
However, since machines do fail, there are two key problems:
-
Atomicity
- How to ensure atomic execution of a transaction that updates data at more than one machine?
-
Consistency
- All live replicas have same value, and each read sees the latest version
Moreover, network link failures can cause further problems although the probability of multiple machines failing is relatively low. In particular, a network partition is said to occur if two live machines in a network are unable to communicate with each other. In presence of partitions, it has been shown that both availability and consistency cannot be guaranteed:
Any distributed data store can provide only two of the following three guarantees:
-
Consistency
Every read receives the most recent write or an error. -
Availability
Every request received by a non-failing node in the system must result in a response. -
Partition tolerance
The system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes.
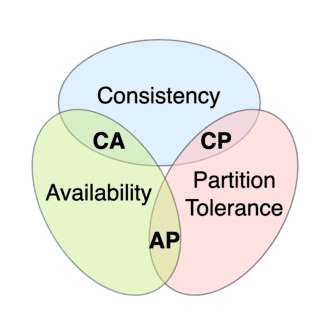
Hence, in the presence of a partition, one is then left with two options: consistency or availability. Opting for consistency over availability means the system will return an error or timeout if it cannot guarantee that the information is up-to-date due to network partitioning. onversely, choosing availability over consistency means the system will always process the query and attempt to return the most recent available version of the information, even if it cannot ensure it is up-to-date due to network partitioning.
MapReduce
The MapReduce paradigm, proposed by Google and being available as Hadoop, provides a platform for reliable, scalable parallel computing, abstracting the issues of a distributed and parallel environment from programmers.
Instead, MapReduce systems provide the programmer a way of specifying the core logic needed for an application, through map() and reduce() functions. And the provided map() and reduce() functions are invoked on the data by the MapReduce system to process data in parallel. Therefore, the programmer does not need to be aware of the plumbing or its complexity.
Motivation
Example 1: Word Counting
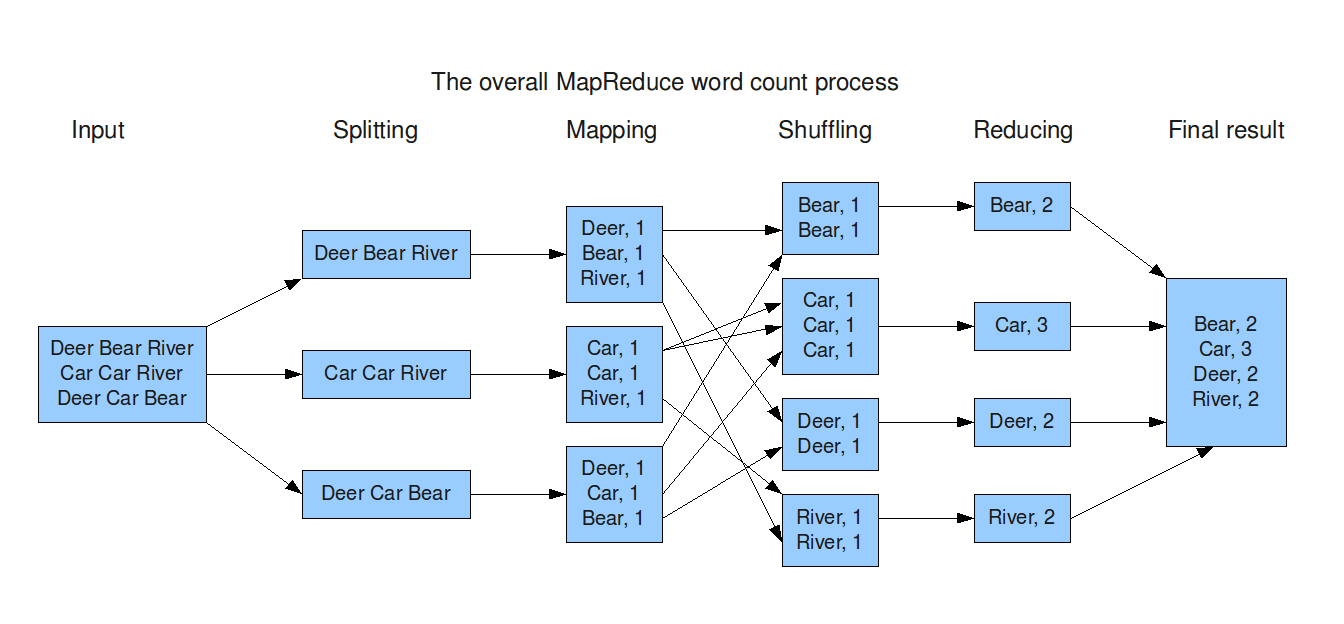
As a motivating example for the use of the MapReduce paradigm, consider the following word count application. Let’s consider the problem of counting the number of occurrences of each word in a large collection of documents. The question is, how to write the parallel program that would run across many machines with each machine processing a part of the files. Then, the following solution is possible:
- Divide documents among workers
- Each worker parses document to find all words, a map function outputs
(word, count)pairs - Partition
(word, count)pairs across workers based on the word - For each word at a worker, a reduce function locally adds up the counts
The MapReduce paradigm conceptualizes the above solution with pseudocode. For the word count application, the map() function could break up each record (line) into individual words and output a number of records, each of which is a pair (word, count). All pairs are then passed to the reduce() function, which combines the list of word counts by adding the counts.
In general, the map() function outputs a set of (key, value) pairs for each input record. And the first attribute (key) of the map() output record is referred to as reduce key, since it is used by the reduce step.
A key issue is that with many files, there may be many occurrences of the same word across different files. In a parallel system, this requires data for different reduce keys to be exchanged between machines, so all the values for any particular reduce key are available at a single machine. This work is done by the shuffle step, which performs data exchange between machines and then sorts the (key, value) pairs to bring all the values for a key together. And finally, the reduce() is called on list of values in each group.
Pseudocode for the map() and reduce() function for the word count program is shown in below:
1
2
3
4
5
6
7
8
9
10
map(String record):
for each word in record
emit(word, 1);
reduce(String key, List value_list):
String word = key;
int count = 0;
for each value in value_list:
count = count + value;
output(word, count);
Example 2: Log Processing
As another example of the use of the MapReduce paradigm, which is closer to traditional database query processing, suppose we have a log file recording accesses to a web site, which is structured as follows:
1
2
3
4
5
6
2013/02/21 10:31:22.00EST /slide-dir/11.ppt
2013/02/21 10:43:12.00EST /slide-dir/12.ppt
2013/02/22 18:26:45.00EST /slide-dir/13.ppt
2013/02/22 18:26:48.00EST /exer-dir/2.pdf
2013/02/22 18:26:54.00EST /exer-dir/3.pdf
2013/02/22 20:53:29.00EST /slide-dir/12.ppt
Our goal is to find how many times each of the files in the slide-dir directory was accessed between 2013/01/01 and 2013/01/31.
In our application, each line of the input file can be considered as a record. The map() function processes this record by extracting individual fields: date, time, and filename. If the date falls within the specified range, the map() function emits a record (filename, 1), indicating that the filename appeared once in that record.
During the shuffle step, values for each reduce key are aggregated into a list. The reduce() function provided by the programmer is then invoked for each reduce key. The function sums the values for each key to determine the total number of accesses for a file.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
map (String key, String record) {
// break up a record into tokens (based on a space character), and store the tokens in array attributes
String attribute[3];
String date = attribute[0];
String time = attribute[1];
String filename = attribute[2];
if date between 2013/01/01 and 2013/01/31 and filename starts with "/slide-dir/"
emit(filename, 1);
}
reduce (String key, List recordlist) {
String filename = key;
int count = 0;
for each record in recordlist
count = count + 1;
output(filename, count);
}
Programming Model
Thus far, we have explored the MapReduce paradigm through motivating examples. As we have observed, the MapReduce paradigm is inspired by the map and reduce operations commonly used in functional programming languages like Lisp. It takes a set of key-value pairs as input, and two user-defined functions come into play.
The map() function is applied to each of a large number of input records, followed by an aggregation process identified by the reduce() function. The map() function is also allowed to specify grouping keys, so that the aggregation defined in the reduce() function is applied within each group, as identified by the grouping key, of the map() output.

And the following figure shows a schematic view of the flow of keys and values through the map() and reduce() functions. In the figure the $\mathrm{mk}_i$’s denote map keys, $\mathrm{mv}_i$’s denote map input values, $\mathrm{rk}_i$’s denote reduce keys, and $\mathrm{rv}_i$’s denote reduce input values.
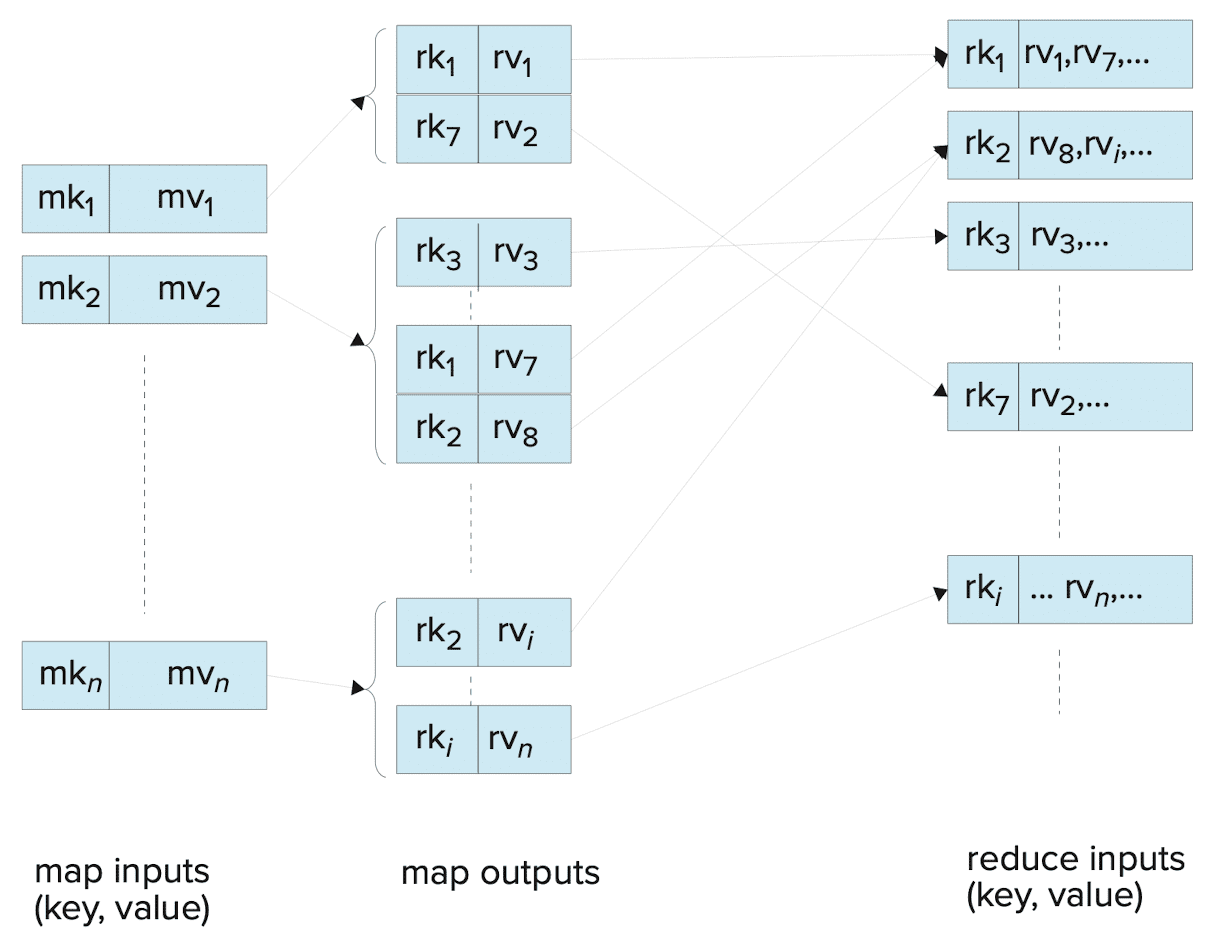
To enable parallel processing, MapReduce systems execute the map() function concurrently on multiple machines, with each map task handling a portion of the data. Likewise, the reduce() functions are executed in parallel across multiple machines, with each reduce task processing a subset of the reduce keys. It is important to note that each invocation of the reduce() function still pertains to a single reduce key.
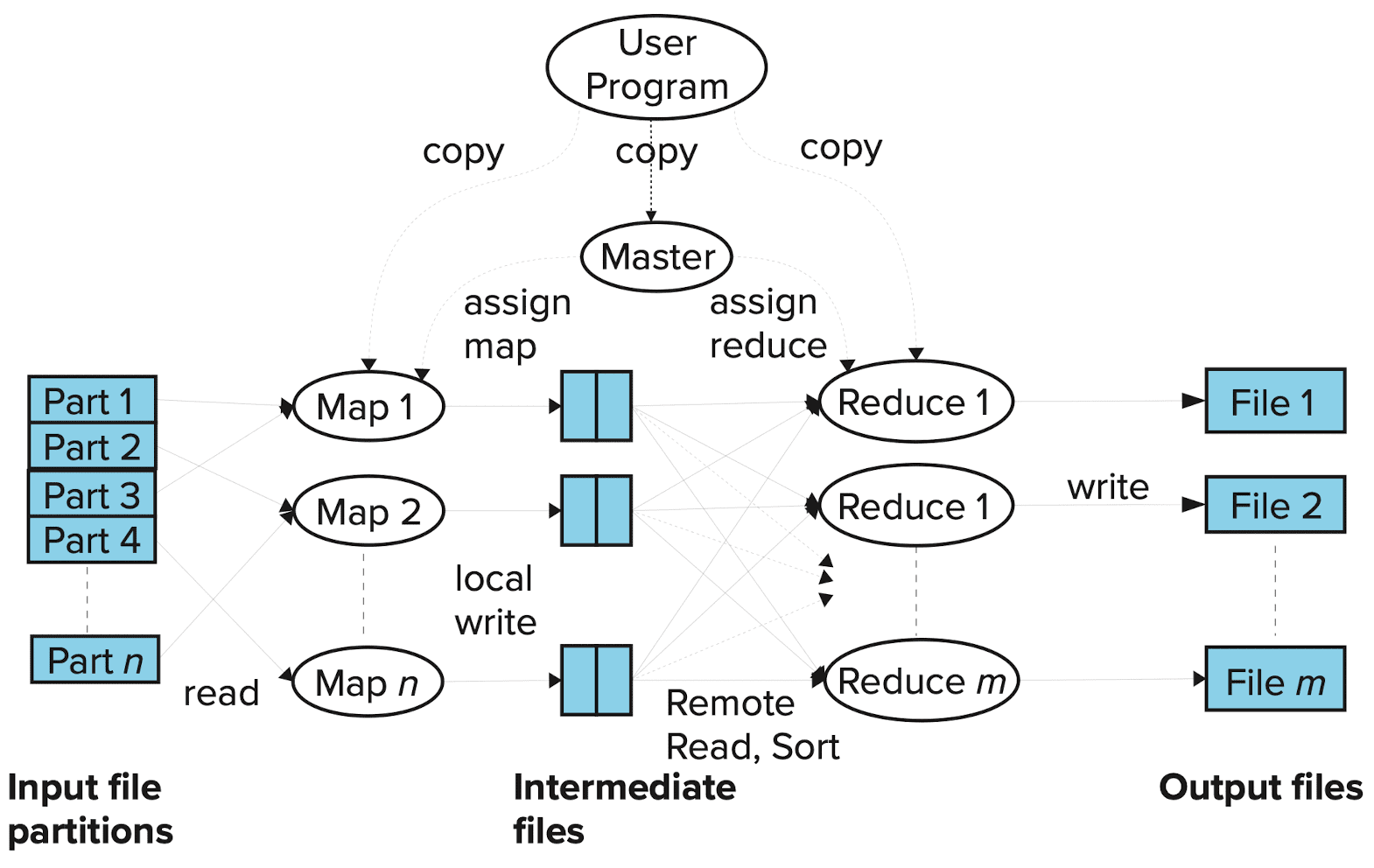
Hadoop MapReduce
MapReduce systems must also parallelize file input and output across multiple machines to avoid the bottleneck of a single machine handling all data. This parallelization can be achieved using a distributed file system, such as the Hadoop File System (HDFS). Google pioneered MapReduce implementations capable of running on thousands of machines (nodes) while transparently handling machine failures. Hadoop is a widely-used open-source implementation of MapReduce, written in Java.

Hadoop requires the programmer to implement map() and reduce() functions as member functions of classes that extend Hadoop Mapper and Reducer classes. And these generic interfaces both take four type arguments, that specify the types of the input key, input value, output key, and output value. For example, Map class in the following pseudocode for word counting implements the Mapper interface with
- Map input key of type
LongWritable, i.e., a long integer - Map input value, which is (all or part of) a document, is of type
Text - Map output key of type
Text, since the key is a word - Map output value of type
IntWritable, which is an integer value
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
public static class Map extends Mapper<LongWritable, Text, Text, IntWritable>
{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException
{
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
context.write(word, one);
}
}
}
public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException
{
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}
A MapReduce job runs a map and a reduce step. And a program may include multiple MapReduce steps, each with its own specific settings for the map and reduce functions. The main() function configures the parameters for each MapReduce job and then executes it. The following pseudocode for word counting demonstrates the execution of a single MapReduce job with the specified parameters:
- The classes that contain the map and reduce functions for the job
- Set by the methods
setMapperClass()andsetReducerClass()
- Set by the methods
- The types of the job’s output key and values
- Set by the methods
setOutputKeyClass()andsetOutputValueClass()
- Set by the methods
- The input format of the job
- Set by the method
job.setInputFormatClass() - Default input format in Hadoop is
TextInputFormat- Map key whose value is a byte offset into the file
- Map value is the contents of one line of the file
- Set by the method
- The directories where the input files are stored and where the output files must be created
- Set by the methods
addInputPath()andaddOutputPath()
- Set by the methods
- And many more parameters!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
public class WordCount {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf, "wordcount");
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}
MapReduce vs. Databases
MapReduce has been extensively utilized for parallel processing by companies like Google, Yahoo, and many others, for tasks such as computing PageRank, building keyword indices, and analyzing web click logs. Many real-world applications of MapReduce cannot be expressed in SQL. However, numerous applications that leverage the MapReduce paradigm for various data processing tasks can be easily expressed in SQL, as MapReduce can be cumbersome for writing simple queries.
Conversely, relational operations such as SELECT, JOIN, aggregation with GROUP BY can also be expressed using MapReduce. SQL queries can be translated into the MapReduce infrastructure (e.g., Apache Hive SQL, Apache Pig Latin, Microsoft SCOPE) for parallel execution. Modern execution engines support not only MapReduce but also other algebraic operations such as JOINs and aggregation natively.
Beyond MapReduce: Algebraic Operations
Relational algebra forms the foundation of relational query processing, allowing queries to be modeled as trees of operations. This concept extends to settings with more complex data types by supporting algebraic operators that can handle datasets containing records with intricate data types, returning datasets with similarly complex records.
Rather than designing relational operations within the MapReduce paradigm, modern generation execution engines have added support for algebraic operations such as JOINs and aggregation. These engines also enable users to create their own algebraic operators, supporting trees of algebraic operators that can be executed in parallel across multiple nodes. Several frameworks facilitate these capabilities; the most widely used today are Apache Tez and Apache Spark. Tez provides a low-level API, and Hive on Tez compiles SQL queries into algebraic operations that run on Tez. Since Tez is not primarily designed for direct use by application programmers, this discussion does not delve further into it.
Algebraic Operations in Spark
Compared to Tez, Apache Spark provides more user-friendly API using a representation called Resilient Distributed Dataset (RDD), a collection of records that can be stored across multiple machines.
- distributed refers to the records being stored on different machines
- resilient refers to the resilience to failure, in that even if one of the machines fails, records can be retrieved from other machines where they are stored.
RDDs can be created by applying algebraic operations on other RDDs, and they can also be lazily computed when needed. Each and every dataset in Spark RDD is logically partitioned across many nodes so that they can be computed on different nodes of the cluster.
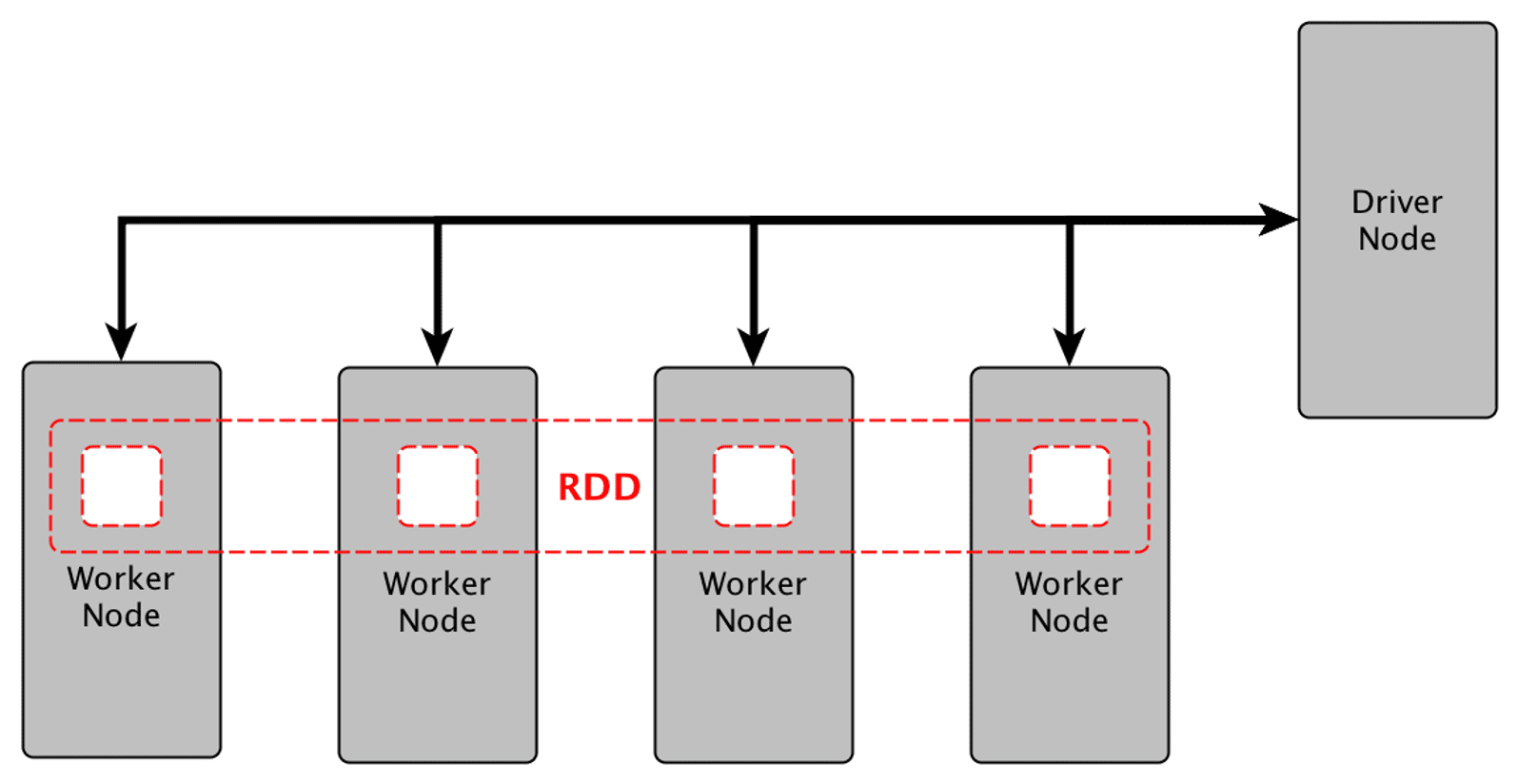
For better understanding, consider the word counting application. The first step in processing data using Spark is to convert data from input representation to the RDD representation, which is done by the spark.read().textfile() function, which creates a record for each line in the input file. Then, there are only two types of operation supported by Spark RDDs:
-
Transformation: creating a new RDD by transforming from an existing RDD
-
map(f): returning a new distributed dataset formed by passing each element of the source through a function $f$; (one output value for each input value) -
filter(f): returning a new dataset formed by selecting those elements of the source on which $f$ returns true; -
flatMap(f): similar to map, but each input item → 0 or more output items; (an arbitrary number, 0 or more values for each input value) -
reduceByKey(f): returning a dataset of $(K, V)$ pairs where the values for each key are aggregated using the given reduce function $f$; - …
-
-
Action: computing and writing a value to the driver program
-
collect(): returning all the elements of the dataset as an array at the driver program -
count(): returning the number of elements in the dataset - …
-
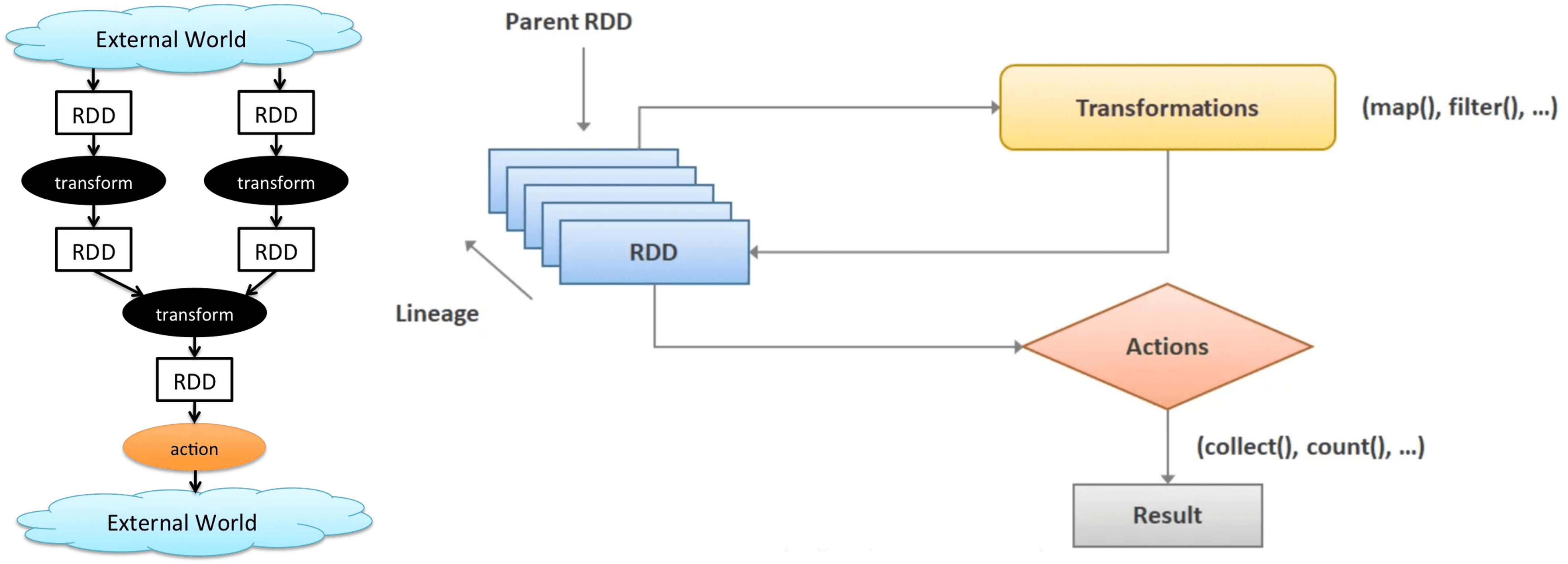
The following pseudocode uses the lambda expression syntax introduced in Java 8, which allows functions to be defined compactly, without even giving them a name:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
SparkSession spark =
SparkSession.builder().appName("WordCount").getOrCreate();
JavaRDD<String> lines = spark.read().textFile(args[0]).javaRDD();
JavaRDD<String> words = lines.flatMap(s -> Arrays.asList(s.split(" ")).iterator());
JavaPairRDD<String, Integer> ones = words.mapToPair(s -> new Tuple2<>(s, 1));
JavaPairRDD<String, Integer> counts = ones.reduceByKey((i1, i2) -> i1 + i2);
counts.saveAsTextFile("outputDir"); // Save output files in this directory
List<Tuple2<String, Integer> output = counts.collect();
for (Tuple2<String, Integer> tuple : output) {
System.out.printIn(tuple);
}
spark.stop();
Algebraic operations in Spark are typically executed in parallel across multiple machines, with RDDs partitioned among the machines.
Another crucial aspect of Spark is that its algebraic operations are executed lazily, rather than immediately. Specifically, the program constructs an operator tree; for example, in preceding pseudocode, textFile() reads data from a file, the subsequent operation flatMap() has the textFile() operation as its child, the mapToPairs() in turn has flatMap() as child, and so on. And the entire tree is executed only when specific functions such as saveAsTextFile() or collect() are invoked. This lazy evaluation allows for query optimization to be performed on the tree before execution.
Streaming Data
Numerous applications require continuous query execution on data that arrive in a continuous manner, referred to as streaming data. Many application domains necessitate real-time processing of incoming data:
- Stock market: stream of trades
- e-commerce site: purchases, searches
- Sensors: sensor readings
- Internet of things
- Network monitoring data
- Social media: tweets and posts can be viewed as a stream
Querying Streaming Data
Data stored in a database are often referred to as data-at-rest, in contrast to streaming data. Unlike stored data, streams are unbounded, and may conceptually continue indefinitely. To address the inherently unbounded nature of streaming data, several approaches have been developed for querying them:
-
Windowing: A stream is broken into windows, and queries are run on windows
- Stream query languages support window operations
- Windows may be based on time or tuples
- e.g. timestamp, number of tuples
- Given information about timestamps of incoming tuples, we can infer when all tuples in a window have been seen
- when tuples have increasing timestamp,
- Or, stream might contain punctuations to specify that all future tuples have timestamp greater that some value
- Briefly, a punctuation $\tau$ indicates that no more tuples having a timestamp greater than $\tau$ will be seen in the stream
-
Continuous queries: Queries written e.g., in SQL, output partial results based on the stream seen so far; query results are updated continuously
- Each incoming tuple may result in insertion, update, or deletion of tuples in the result of the continuous query
- However, the user would be flooded with a large number of updates
-
Algebraic operators on streams:
- Each operator consumes tuples from a stream and outputs tuples
- Operators can be written e.g., in an imperative language
- Operators may maintain state, allowing them to aggregate incoming data
-
Pattern matching:
- Queries specify patterns, and a system detects occurrences of patterns and triggers actions
- Such systems are called Complex event processing (CEP) systems
- e.g., Microsoft StreamInsight, Flink CEP, Oracle Event Processing
- Queries specify patterns, and a system detects occurrences of patterns and triggers actions
Many stream processing systems operate entirely in-memory and do not persist data, allowing them to generate results with minimal delay and enabling rapid responses based on the analysis of streaming data. Conversely, the incoming data may also need to be stored in a database for subsequent processing.
To support both querying patterns, the lambda architecture duplicates a stream into two, directing one copyto a stream processing system and the other to a database for storage. (However, this separation of the streaming and database system often results in duplicated querying efforts.)
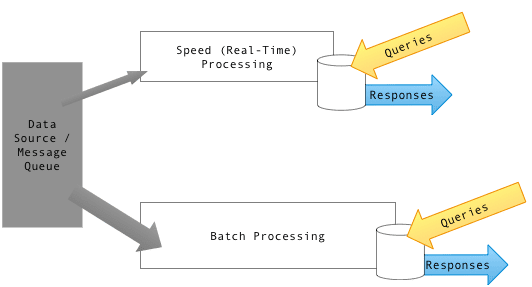
Stream Extensions to SQL
Recall that SQL also supports windowing operations. However, streaming query languages often support more window types:
-
Tumbling window
- e.g., Hourly windows, windows don’t overlap but are adjacent to each other;
-
Hopping window
- e.g., Hourly window computed every 20 minutes;
-
Sliding window
- Window of specified size (based on timestamp interval or number of tuples) around each incoming tuple
-
Session window
- identified by a user and a time-out interval, and contains a sequence of operations such that each operation occurs within the time- out interval from the previous operation;
- e.g. if the time-out is 5 minutes, and a user performs an operation at 10 AM, a second operation at 10:04 AM, and a third operation at 11 AM, then the first two operations are part of one session, while the third is part of a different session;
For example, in Azure Stream Analytics, when a relation order(id, date_time, item_id, amount) is given, the total order amount for each item for each hour can be specified by the following tumbling window:
1
2
3
SELECT item, System.Timestamp AS window_end, SUM (amount)
FROM order TIMESTAMP BY date_time
GROUP BY item_id, TUMBLINGWINDOW (hour, 1)
SQL extensions for streams distinguish between streams, where tuples have implicit timestamps and are expected to receive a potentially unbounded number of tuples, and relations, whose content is fixed at any given time. For instance, customers, suppliers, and items associated with orders are treated as relations rather than streams. Consequently, the results of queries with windowing are treated as relations rather than streams.
Furthermore, many systems support stream-relation joins, which produce a stream. In the case of stream-stream joins, a challenge arises: a tuple early in one stream may match a tuple that appears much later in the other stream, necessitating the storage of the entire stream for a potentially unbounded duration. To avoid this issue, stream-stream joins are often constrained by join conditions that specify a bound on the timestamp gap between matching tuples (e.g., tuples must be at most 30 minutes apart in timestamp)
Algebraic Operations on Streams
While SQL queries on streaming data are quite useful, there are many applications where SQL queries are not a good fit. With the algebraic operations approach to stream processing, user-defined code can be provided for implementing an algebraic operation; a number of predefined algebraic operations, such as selection and windowed aggregation, are also provided.
To perform computation, tuples in streams need to be routed to operators. Apache Storm and Kafka are widely used implementations that support such routing of data. The logical routing of tuples can be performed by creating directed acyclic graph (DAG), or publish-subscribe (pub-sub) representations, used in Apache Storm and Apache Kafka, respectively.
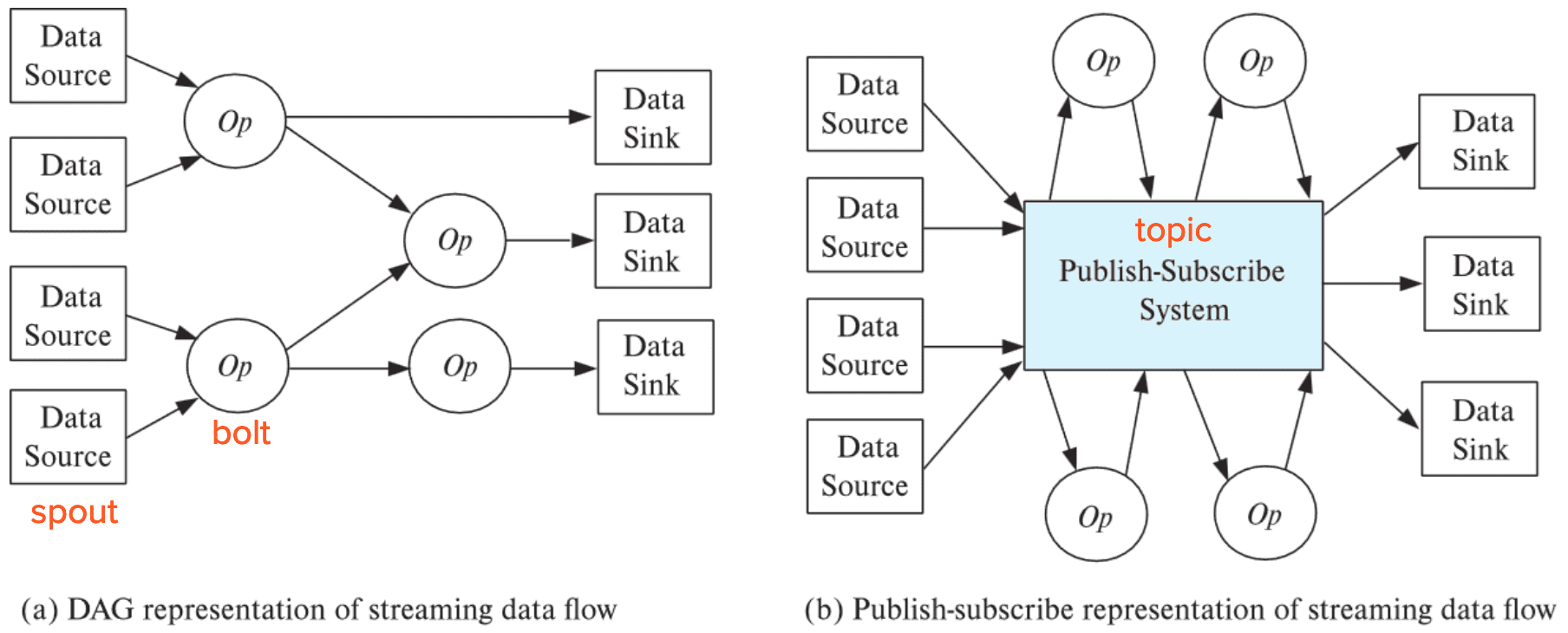
-
Directed Acyclic Graph (DAG)
- Nodes specify operators
- called bolts in the Storm system
- Edges define the flow of tuple
- The entry points to the stream-processing system are the data-source nodes of the DAG
- called spouts in the Storm system
- consume tuples from the stream sources and inject them into the stream-processing system
- The exit points of the stream-processing system are data-sink nodes
- tuples exiting the system through a data sink may be stored in a data store or file system or may be output in some other manner
- Nodes specify operators
-
Publish-subscribe (pub-sub)
- provide convenient abstraction for processing streams
- Tuples in a stream are published to a topic
- Consumers (Operators) subscribe to a topic
- Whenever data is published to a particular topic, a copy of the document is routed to all subscribers who have subscribed to that topic.
- Operators can also publish their outputs back to the system with an associated topic.
- Advantage: operators can be added to the system, or removed from it, with relative ease
- Parallel pub-sub systems allow tuples in a topic to be partitioned across multiple machines
- Apache Kafka is a popular parallel pub-sub system widely used to manage streaming data
- provide convenient abstraction for processing streams
Graph Databases
Graph Data Model
Graphs are a very general data model in computer science and an important type of data that databases need to deal with.
- ER model of an enterprise
- Every entity is a node;
- Every binary relationship is an edge;
- Ternary and higher degree relationships can be modeled as binary relationships;
- Road network
- Road intersections are node;
- Road links between intersections are edges;
Graphs can be modeled as relations:
node(ID, label, node_data)edge(fromID, toID, label, edge_data)
Although graph data can be easily stored in relational databases, graph databases such as the widely used Neo4j provide several extra features. For example, they allow relations to be identified as representing nodes or edge. Suppose the input graph has nodes corresponding to students (stored in a relation student) and instructors (stored in a relation instructor), and an edge type advisor from student to instructor. Then, we can then write the following query in Cypher query language supported by Neo4j:
1
2
3
MATCH (i:instructor)<-[:advisor]-(s:student)
WHERE i.dept_name='Comp. Sci.'
RETURN i.ID AS ID, i.name AS name, collect (s.name) AS adviseees
Relationships are represented in Cypher with arrows (e.g., ->) indicating the direction of a relationship. This query basically performs a join of the instructor, advisor and student relations, and performs a GROUP BY on instructor ID and name, and collects all the students advised by the instructor into a set called advisees.
Recursive traversal of edges is also possible. Suppose prereq(course_id, prereq_id) is modeled as an edge. Transitive closure can be done as follows:
1
2
MATCH (c1:course)-[:prereq *1..]->(c2:course)
RETURN c1.course_id, c2.course_id
*1.. indicates we want to consider paths with multiple prereq edges, with a minimum of 1 edge (with a minimum of 0, a course would appear as its own prerequisite).
Parallel Graph Processing
There are many applications that need to process very large graphs, and parallel processing is key for such applications. And there are two popular approaches for parallel graph processing:
- MapReduce and algebraic frameworks
- Bulk synchronous processing (BSP) framework
Bulk Synchronous Processing (BSP)
Multiple iterations are required for any computations on graphs. Although MapReduce/algebraic frameworks often have high overheads per iteration, Bulk Synchronous Processing (BSP) frameworks have much lower per-iteration overheads. It frames graph algorithms as computations associated with vertices that operate in an iterative manner. The graph is typically stored in memory, with vertices partitioned across multiple machines; most importantly, the graph does not have to be read in each iteration.
Google’s Pregel system popularized the BSP framework, and the Apache Giraph is an open-source version of Pregel. ALso, Apache Spark’s GraphX component provides a Pregel-like API.
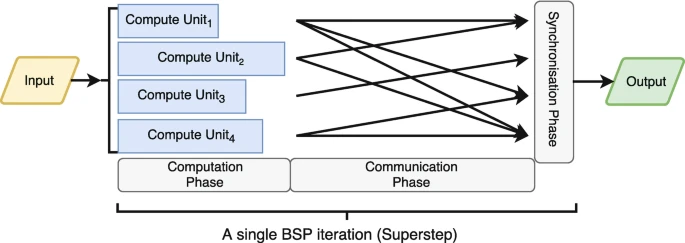
Each vertex (node) of the graph has data (state) associated with it. Much like how programmers provide the map() and reduce() functions in the MapReduce framework, in the BSP framework, programmers specify methods that are executed for each graph node. These methods can transmit messages to and receive messages from adjacent nodes. During each iteration, called a superstep, the method linked to each node is executed; it processes any incoming messages, updates the node’s state, and may optionally transmit messages to neighboring nodes. Messages sent in one iteration are received by the recipients in the subsequent iteration. The computation’s outcome is embedded in the state at each node, which can be aggregated and presented as the final result.
References
[1] Silberschatz, Abraham, Henry F. Korth, and Shashank Sudarshan. “Database system concepts.” (2011).
[2] Wikipedia, CAP theorem
[3] Wikipedia, Lambda Architecture
Leave a comment