
[Embodied AI] Improving VLA with RL
Recent research has successfully incorporated large vision-language models (VLMs) into low-level robotic control through supervised fine-tuning (SFT) using expert robotic datasets, giving rise to what are now referred to as vision-language-action (VLA) models. While these VLA models exhibit considerable capability, fine-tuning via behavior cloning (BC) imposes an upper bound on their generalization potential and scalability due to the demonstration collection.
In response, recent efforts have attempt to integrate reinforcement learning (RL) into VLA learning pipeline to address this limitation. By leveraging RL for fine-tuning or for curating demonstration data, researchers are increasingly able to refine these initially broad but suboptimal VLA models into agile robotic policies, equipped with both high precision and robust generalization.
Iterative Reinforcement Learning
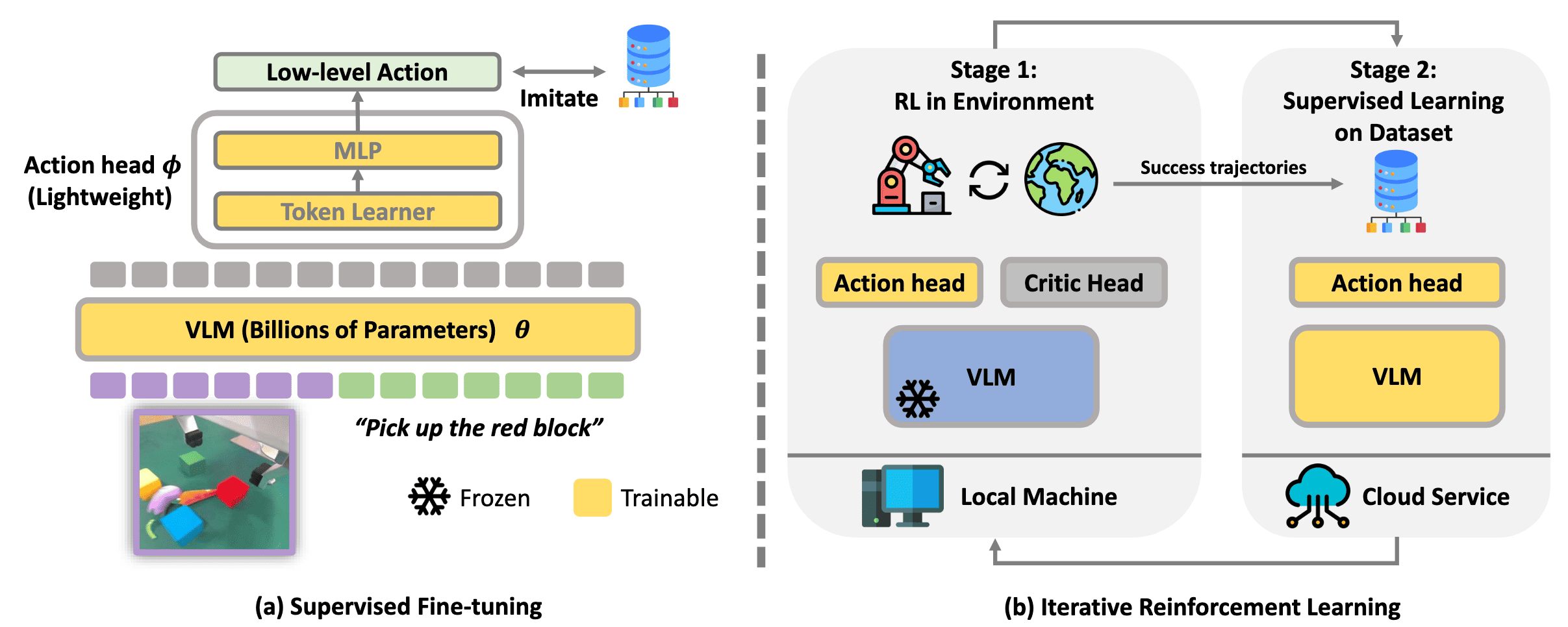
Naively deploying online RL process with large neural networks often leads to severe instability and catastrophic forgetting pre-trained knowledge. To mitigate this and effectively refine pre-trained VLA models, Guo et al. ICRA 2025 iterates between stages of online RL and supervised learning:
- Stage 1: RL with frozen VLM
- Stage 2: Behavior Cloning using expert + collected dataset
This approach is applied across hybrid environments that mixed RL environments (Metaworld and Franka Kitchen) and the real-world Panda Manipulation. For real-world tasks lacking a ground-truth reward function, one can train a reward classifier such as VICE or alternatively, define a handcrafted reward when the robot’s internal state provides a reliable measure of success.
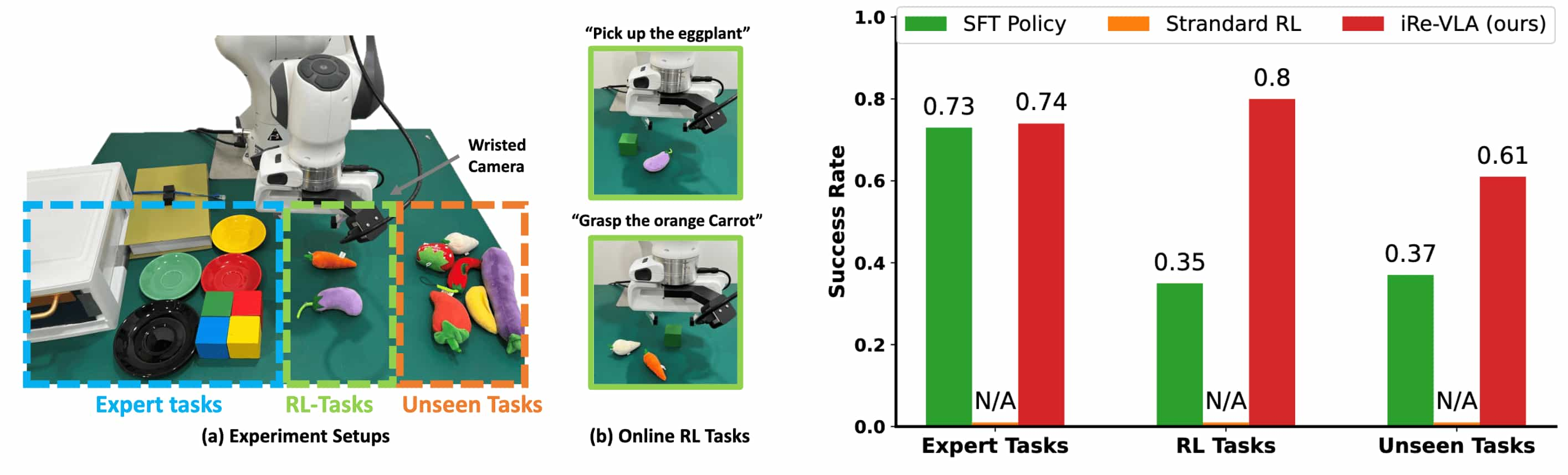
This iterative process offers numerous advantages:
-
(a) Improved Performance in both original and RL Tasks
- The agent continues to refine its capabilities in both seen expert tasks and RL tasks through online interaction.
-
(b) Improved Generalization in Unseen Tasks
- As the agent tackles an increasing variety of tasks automatically, its capacity to generalize improves in tandem.
- e.g., after mastering four types of window tasks in Metaworld, the agent effectively generalized to windows of unseen colors and shapes.
Reinforcement Learning Distilled Generalists (RLDG)
Recent advances in robotic foundation models have paved the way for generalist policies capable of adapting to diverse tasks. While these models show impressive flexibility, their performance heavily depends on the quality of their training data. Furthermore, previous approaches typically rely on fine-tuning VLA models with a limited number of demonstrations (e.g. Open-VLA fully fine-tunes the model with 10 to 150 demonstrations). These demonstrations, often obtained via human teleoperation, are inherently unscalable and incur significant costs.
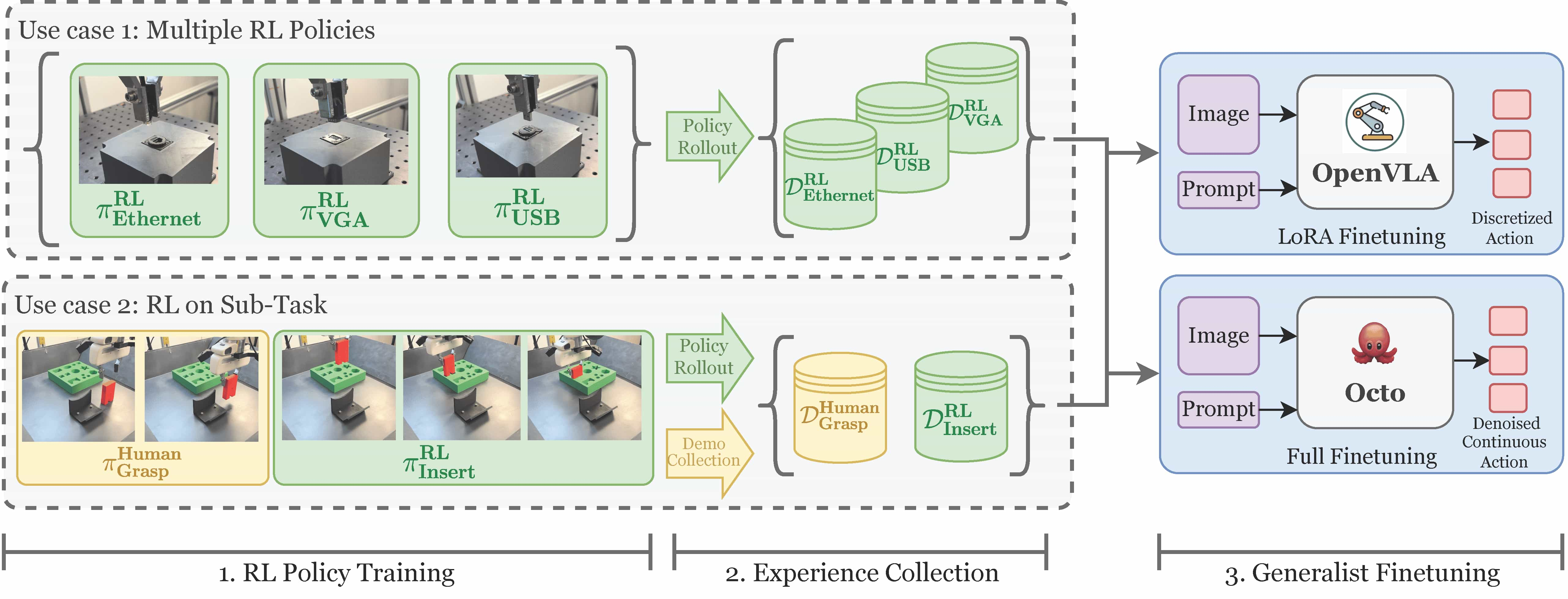
Reinforcement Learning Distilled Generalists (RLDG) leverages RL to generate high-quality training data for fine-tuning generalist policies, improving the performance and generalizability of pre-trained VLA.
- RL Policy Training
Solve small, narrow tasks with RL for multiple tasks (e.g. $\pi_\texttt{ethernet}$, $\pi_\texttt{USB}$, $\pi_\texttt{VGA}$, ...) - Experience Collection
Collect data of downstream tasks with trained RL agent. - Generalist Supervised Fine-Tuning
Finetune VLA model with supervised learning with those data.
The authors evaluate the effectiveness of RLDG across four real-world manipulation tasks that present unique challenges. These include high-precision, contact-rich tasks that often hinder the performance of generalist models, and complex multi-stage assembly tasks.

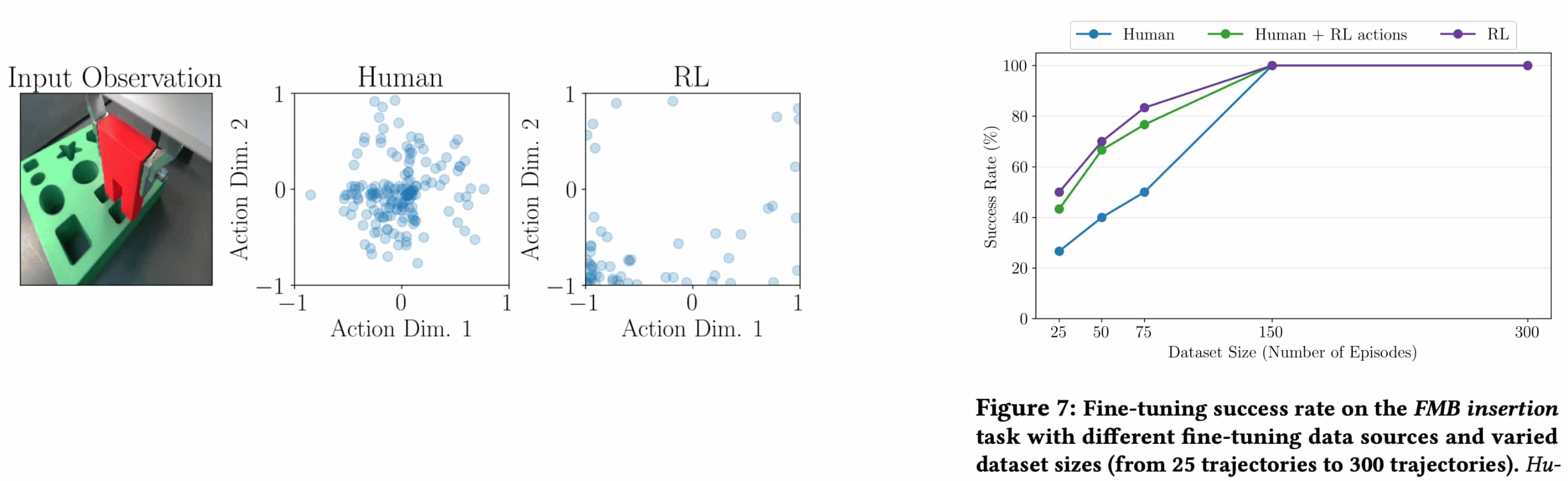
In both OpenVLA and Octo, fine-tuning with RL-generated demonstrations consistently surpasses performance achieved through human-collected data. When compared to human demonstrations, fine-tuning generalist policies using RLDG demonstrates superior sample efficiency for both in-distribution and unseen tasks: VLA with RLDG reached a $100\%$ success rate with just $45$ RL episodes, whereas human demonstrations required $300$ episodes to attain equivalent performance.
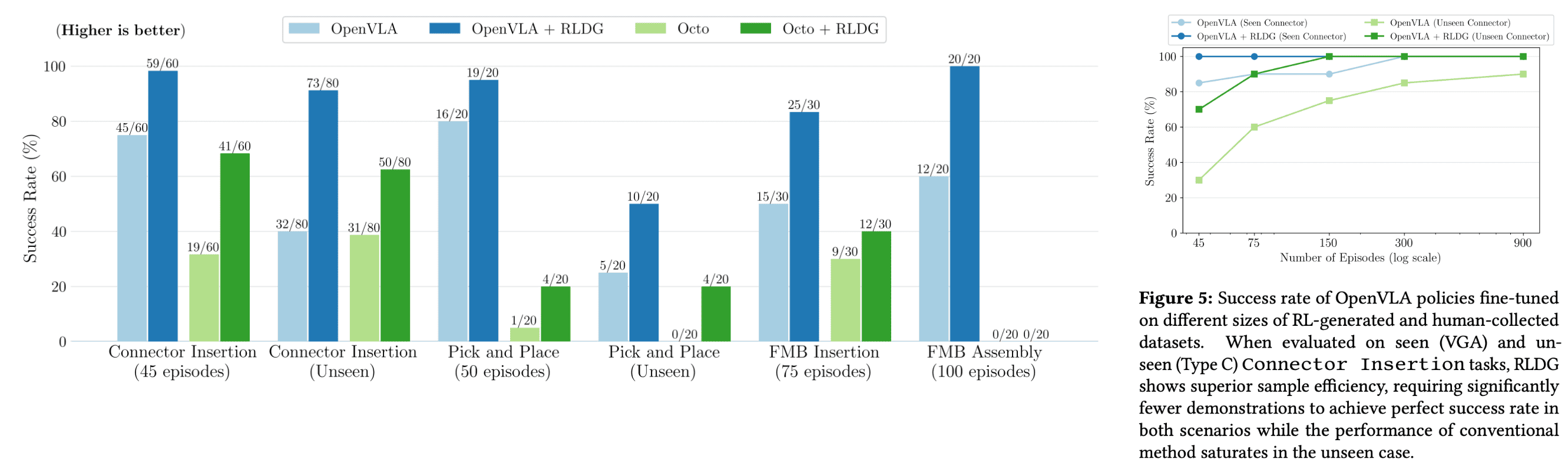
The authors argued that RL data can surpass human-collected data, particularly because RL excels at fine-grained control, unlike human teleoperation. Since the tasks under study demand precise, nuanced manipulation, it is also hard for human teleoperator and human-collected data is not optimal anymore. If we can make reward function appropriately, an RL-derived policy can outperform its human counterpart in such scenarios.
In the following figure (left), the RL action distribution demonstrates a higher concentration of probability in the correct direction (bottom-left) that guides the end-effector towards the insertion point In contrast, the human action distribution clusters near the center, showing only a slight bias in the correct direction. This highlights that RL actions are more optimal than human actions, resulting in the better sample efficiency for fine-tuning in right figure.
References
[1] Guo et al. “Improving Vision-Language-Action Model with Online Reinforcement Learning”, ICRA 2025
[2] Xu et al. “RLDG: Robotic Generalist Policy Distillation via Reinforcement Learning”, ICRA 2025
Leave a comment