
[Generative Model] Personalization with Selectively Informative Description (SID)
In text-to-image personalization, an important challenge is the overfitting of generated images to biases inherent in the reference images. These biases are generally entangled in the subject embedding, leading to their undesired manifestation in the generated images. This undesired entanglement not only causes the biases from the reference images to be reflected in the generated outputs but also significantly reduces the alignment of the generated images with the specified generation prompt.

To address this challenge, selectively informative description (SID) proposed by Kim et al. CVPR 2024 simply modifies the training text descriptions of the reference images by integrating detailed specifications of the “undesired objects” into the descriptions. Since text-to-image diffusion models are trained for alignments, adding text descriptions that accurately describe non-subject elements helps ensure that these parts of the reference images align with the corresponding text descriptions. Consequently, this prevents the undesired objects from accidentally becoming associated with the special token $\textrm{[V]}$.

Embedding Disentanglement with SID
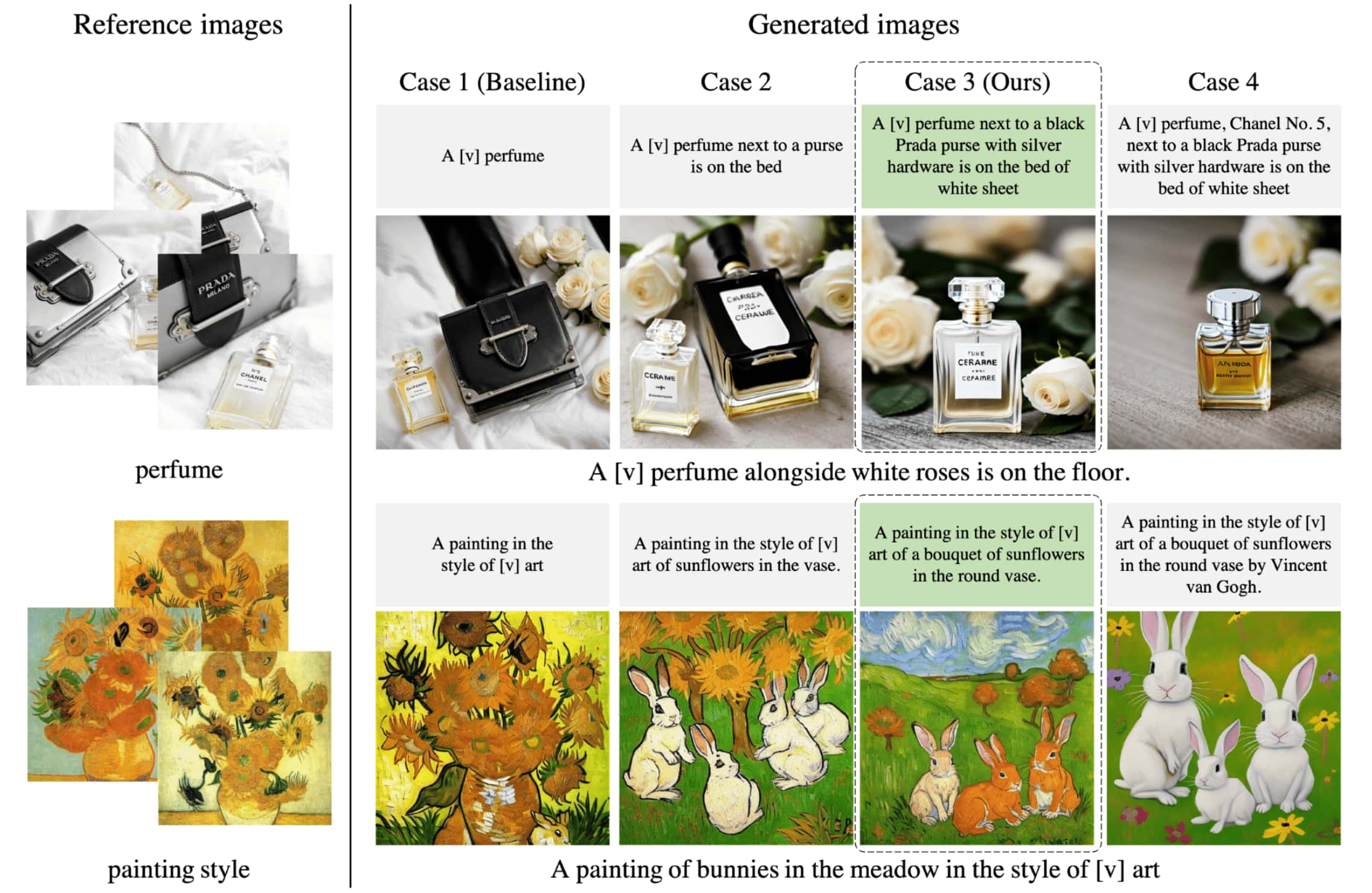
The goal of SID is to develop training train descriptions that have an appropriate level of information to effectively isolate the subject of interest, even when the reference images are biased. The authors considered four cases of train descriptions, categorized based on whether they provide only class identification or additional informative specifications about both the subject and undesired objects.
In the following figure, two example sets of the resulting images are shown.
- Case 1
- the model often struggles with the bias in the reference images due to the embedding entanglement in $\textrm{[V]}$
- Case 2, 3
- both Case 2 and Case 3 can provide a significant improvement over Case 1.
- Case 3 (SID) often outperforms Case 2 in terms of entanglement reduction.
- Case 4
- the subject details described in the informative specifications are disentangled from $\textrm{[V]}$.
- this occurs because of the alignment between the subject’s informative specifications in the text and the subject details in the images.
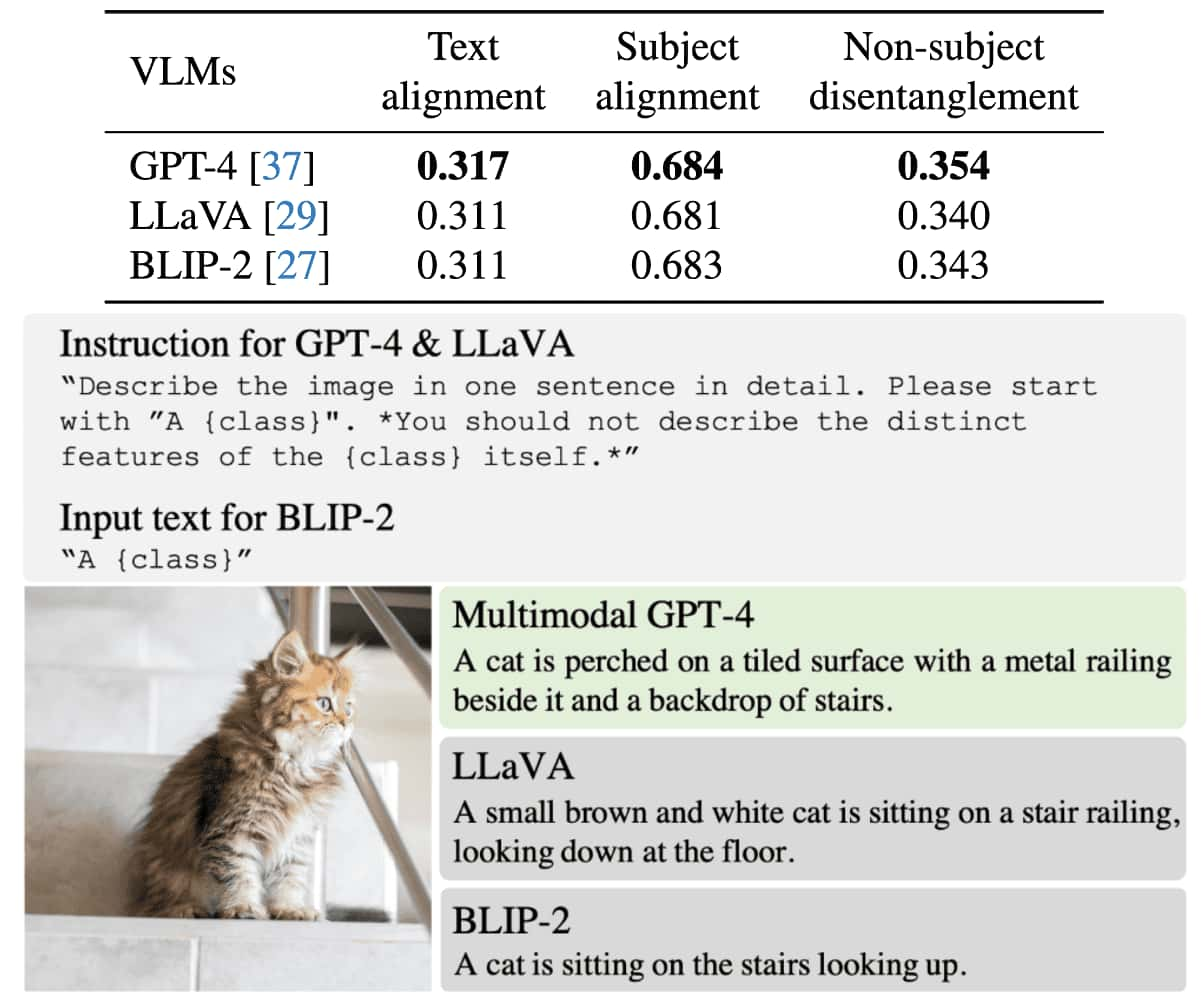
SID Generation with VLM
Generating SID for each reference image can be demanding and time-consuming for humans. Therefore, the authors adopted image captioning VLM for an automatic generation of SID. Comparing with LLaVA and BLIP-2, the multi-modal GPT-4 demonstrates superior performance in both quantitative and qualitative evaluations when used for generating SIDs. (The quantatitve measures will be introduced in the analysis sections.)
Analysis
Cross-Attention Map
To visualize embedding disentanglement, the authors employed the cross-attention map, which highlights the pixels associated with the text token $\textrm{[V]}$ describes. As a result, the informative specification of the non-subject elements highly reduces the spread of attention. While DreamBooth’s identifier tends to mistakenly focus on undesired objects in various biased scenarios, SID-enhanced DreamBooth consistently exhibits highly accurate attention concentrated on the subject.

Alignment & Disentanglement Measures
The widely used image-alignment score is often significantly affected by background entanglement, thereby being unsuitable for analyzing undesired embedding entanglements. To better evaluate embedding disentanglements, the authors introduced two new measures: subject-alignment and non-subject-disentanglement.
For given set of reference images \(R = \{ r_n \}_{n=1}^N\), let \(G = \{ g_m \}_{m=1}^M\) be a set of generated images with a common generation prompt $p$. Additionally, define CLIP image and text encoders followed by normalization:
\[\begin{aligned} & f_\texttt{img}: \mathcal{I} \to \mathbb{R}^D \\ & f_\texttt{txt}: \mathcal{T} \to \mathbb{R}^D \end{aligned}\]respectively. Also define a subject segmenetation function:
\[s: \mathcal{I} \to \{ 0, 1 \}^{H \times W}\]implemented as Grounded-Segment-Anything conditioned on the subject’s class name. Then, the subject-alignment $\mathrm{SA}$ and the non-subject-disentanglement $\mathrm{NSD}$ are defined using the average pairwise cosine similarity between generated images $g$ and subject (or non-subject) segments of reference images $r$ in the CLIP-embedding space:
\[\begin{aligned} \mathrm{SA} & = \texttt{Avg}_{n, m}\left( f_\texttt{img} (r_n \odot s (r_n)) \cdot f_\texttt{img} (g_m) \right) \\ \mathrm{NSD} & = 1 - \texttt{Avg}_{n, m}\left( f_\texttt{img} (r_n \odot \left( 1 - s (r_n) \right)) \cdot f_\texttt{img} (g_m) \right) \end{aligned}\]A higher $\mathrm{SA}$ indicates superior preservation of the subject’s identity. Elevated $\mathrm{NSD}$ values signify a reduction in undesired embedding entanglements. Additionally, we can evaluate text-alignment $\mathrm{TA}$ between the generation prompt $p$ and generated images $g$ (The identifier $\textrm{[V]}$ should be removed from $p$ when evaluating $\mathrm{TA}$):
\[\mathrm{TA} = \texttt{Avg}_{n, m}\left( f_\texttt{txt} (p) \cdot f_\texttt{img} (g_m) \right)\]Increased $\mathrm{TA}$ suggests that the generated images align more closely with the generation prompt.
Consequently, the authors observed that SID-integrated counterparts of existing personalization methods showed substantial improvements in terms of $\mathrm{SA}$, $\mathrm{NSD}$, and $\mathrm{TA}$ in most cases. Especially, in subject-alignment $\mathrm{SA}$, the improvements frequently exhibited negative values with a significant margin. This is attributed to the subject overfitting in the existing models, particularly evident in scenarios like pose bias. The negative margin indicates that SID effecitvely mitigates this overfitting, even when only a single reference image is provided.
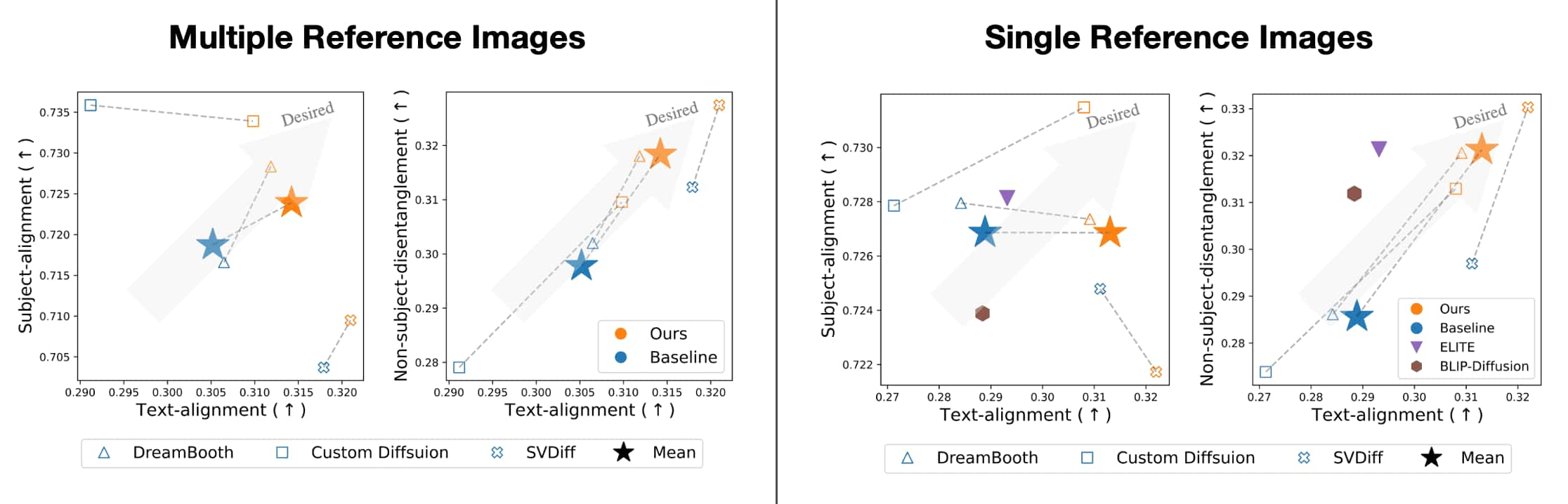
Moreover, when SID-integration is compared to two alternatives: negative prompt and segementation mask, SID demonstrates superior $\mathrm{NSD}$ and $\mathrm{TA}$.

Limitations
Imperfection of VLM
While the multi-modal GPT-4 typically generates descriptions that closely follow the provided instructions, occasional failures do occur. The following figure illustrates some of these failure cases. In (a), GPT-4’s description includes an overly detailed specification of the label on the jar, causing the generated image to omit the subject’s label. In (b), the description mistakenly refers to the tail of the cat toy as a walking stick, leading to the omission of the tail in the generated image.

Undesired entanglement of strong facial expressions
When the reference images exhibit strong facial expressions, SID-integrated models often struggle to modify the subject’s facial expression according to the generation prompt. This issue is due to the absence of text descriptions of the subject’s facial expressions in the VLM-generated SID, leading to an undesired entanglement of these expressions in the subject embedding. Therefore, manually designing the SID to describe the subject’s facial expression can be an effective solution to this issue.

Leave a comment