
[LLM] Prompting
Within the context of Large Language Models (LLMs), prompting denotes the technique of presenting a model with a carefully structured input to generate a desired output or perform a task. For example, to instruct an LLM to translate a sentence from English into Chinese, one might structure the prompt thus:
1
2
3
Translate the text from English to Chinese.
Text: The early bird catches the worm.
Translation: ___
Prompting is vital for LLMs because it directly affects how well these models understand and respond to user queries. A well-crafted prompt can help the LLM generate more accurate, relevant, and appropriate answers. Moreover, this process can be improved over time; by reviewing the LLM’s responses, users can adjust their prompts to better suit their needs.
Given its importance, prompt design has emerged as an essential proficiency among LLM practitioners and developers. Consequently, this has spurred the rise of a research area called prompt engineering, a field focused on creating effective prompts to make LLMs more useful in real-world applications.
General Prompt Design
In-Context Learning
An important concept in prompting is in-context learning. By adding new information to the context, such as problem-solving demonstrations, when prompting LM, we enable it to learn how to solve problems from this context. For instance, consider this example of prompting an LLM with a few sentiment polarity classification demonstrations:
1
2
3
4
Example 1: We had a delightful dinner together. -> Label: Positive
Example 2: I’m frustrated with the delays. -> Label: Negative
What is the label for "That comment was quite hurtful."?
Label: ___
Since model parameters remain unchanged during this process, in-context learning serves as an efficient method to activate and reorganize pre-trained knowledge without requiring additional training or fine-tuning. This allows LLMs to rapidly adapt to new tasks, extending the capabilities of pre-trained models without task-specific modifications.
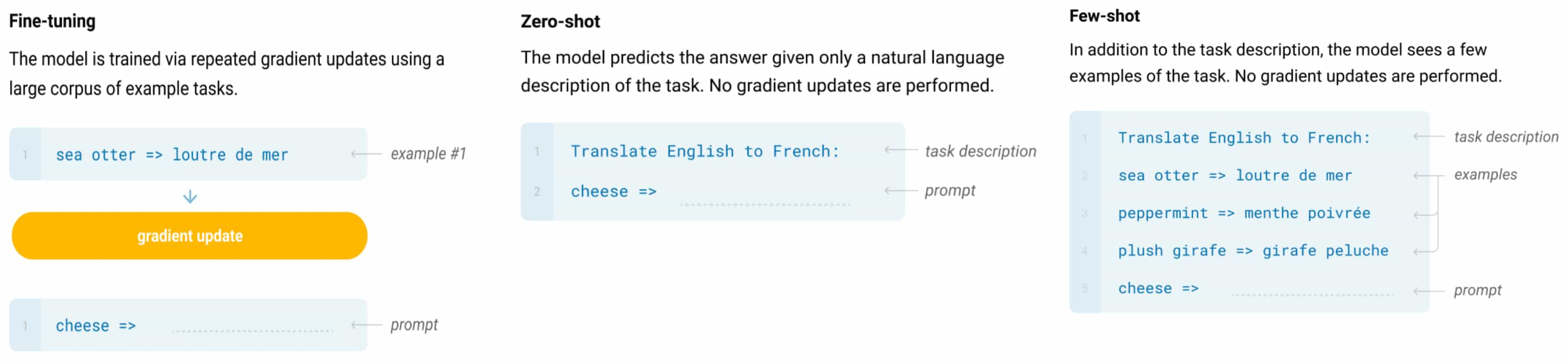
Language Models are Few-Shot Learners
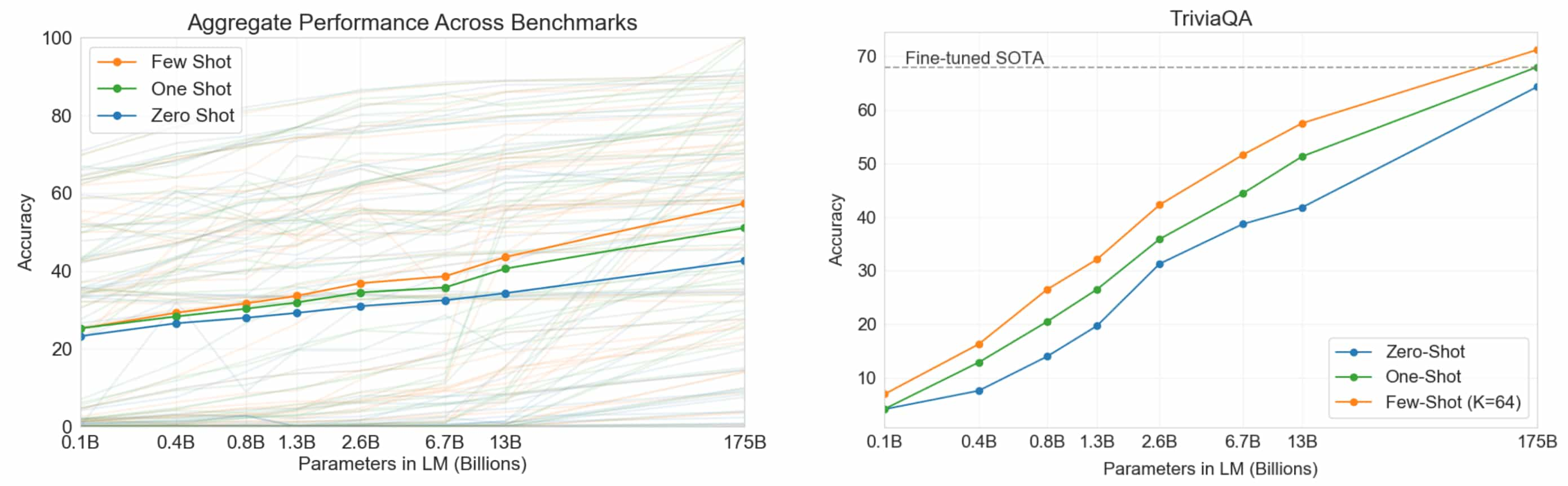
To enhance LLM’s performance on a specific domain or task, a key limitation before in-context learning was the need for 1,000 to 10,000 examples for task-specific fine-tuning. Brown et al. 2020 demonstrate that scaling up language models significantly improves task-agnostic, few-shot performance Their research shows that through few-shot prompting—providing a few task examples along with the task description—GPT-3 achieves state-of-the-art results on various NLP benchmarks, surpassing traditional fine-tuning methods.
Specifically, the authors showed that LLM performance improves consistently with model size in both zero-shot and few-shot settings. However, few-shot performance increases more rapidly, suggesting that larger models utilize in-context knowledge more efficiently. With a higher number of few-shot prompts ($K=64$), LLMs can even outperform fine-tuned variants.
Advanced Prompting Methods
While in-context learning ushers in the era of LLM prompting, standard few-shot prompting struggles with tasks that require reasoning, such as mathematics. To enhance LLM performance on complex reasoning tasks, techniques like chain-of-thought prompting have been proposed.
Chain-of-Thought (CoT)
Chain of Thought (CoT) methods provide a straightforward way to prompt LLMs to generate step-by-step reasoning for complex problems, mimicking human-like problem-solving. nstead of directly reaching a conclusion, CoT instructs LLMs to produce reasoning steps or learn from demonstrations of detailed reasoning provided in the prompts.
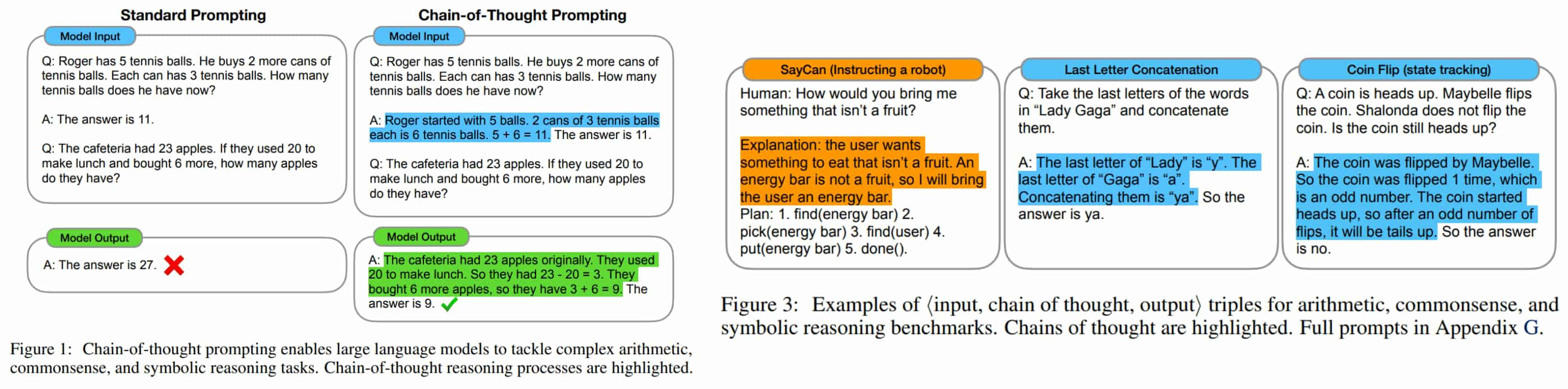
The benefits of CoT prompting are numerous:
- Divide-and-Conquer
CoT enables LLMs to break down complex problems into smaller, sequential reasoning steps. - Explainable & Trustworthy
CoT makes the reasoning process more transparent and interpretable. CoT enhances the transparency and interpretability of the reasoning process. - Plug-and-Play
CoT is an in-context learning approach, and thus, it is applicable to most well-trained, off-the-shelf LLMs and provides efficient ways to adapt LLMs to different types of problems.
Indeed, CoT prompting yields significant performance improvements for complex problems requiring reasoning, often surpassing task-specific fine-tuned models.
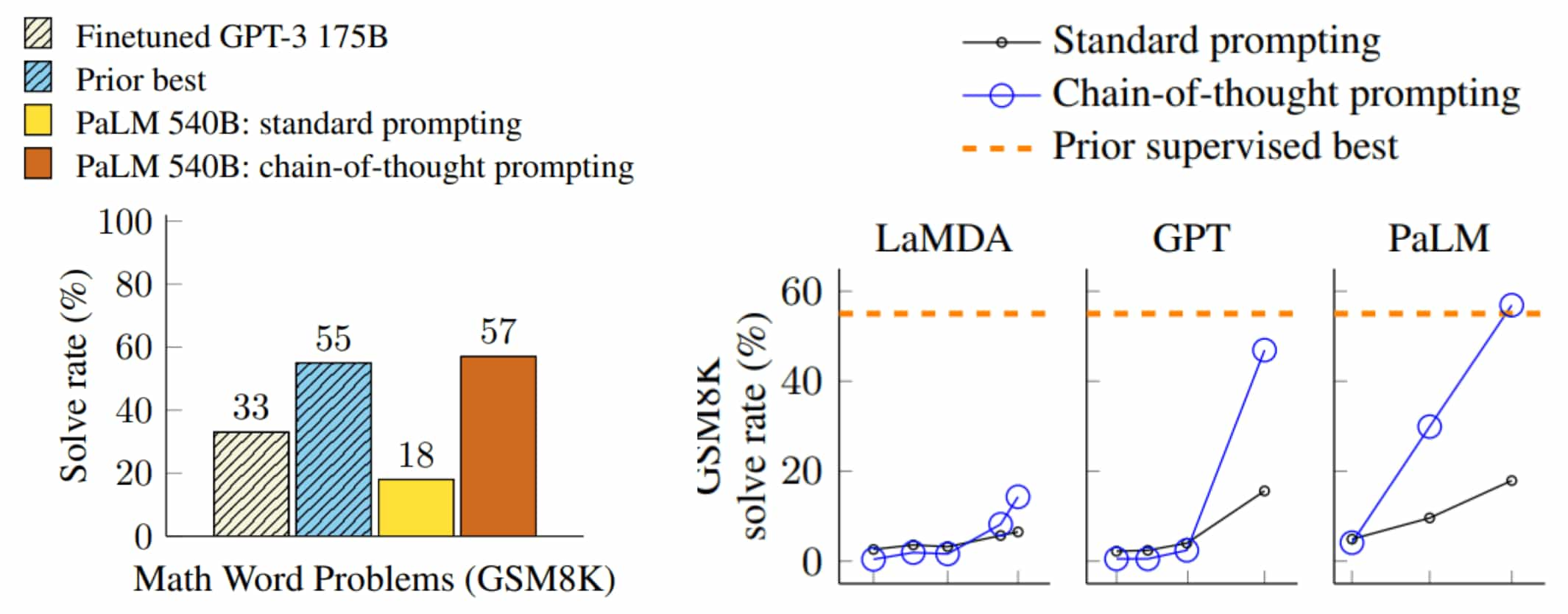
Emergent Ability of CoT
A key insight from CoT prompting is its emergence as a capability in large models, which does not significantly benefit smaller models. CoT prompting leads to larger performance gains for tasks requiring complicated reasoning, such as mathematics and symbolic reasoning:
- In large models, CoT improves both math and symbolic reasoning (relatively easy tasks).
- In small models, CoT improves symbolic reasoning but not math.
Intuitively, the performance boost occurs when the model can reason through sub-problems, suggesting that this ability is more closely tied to the model’s performance than its size.
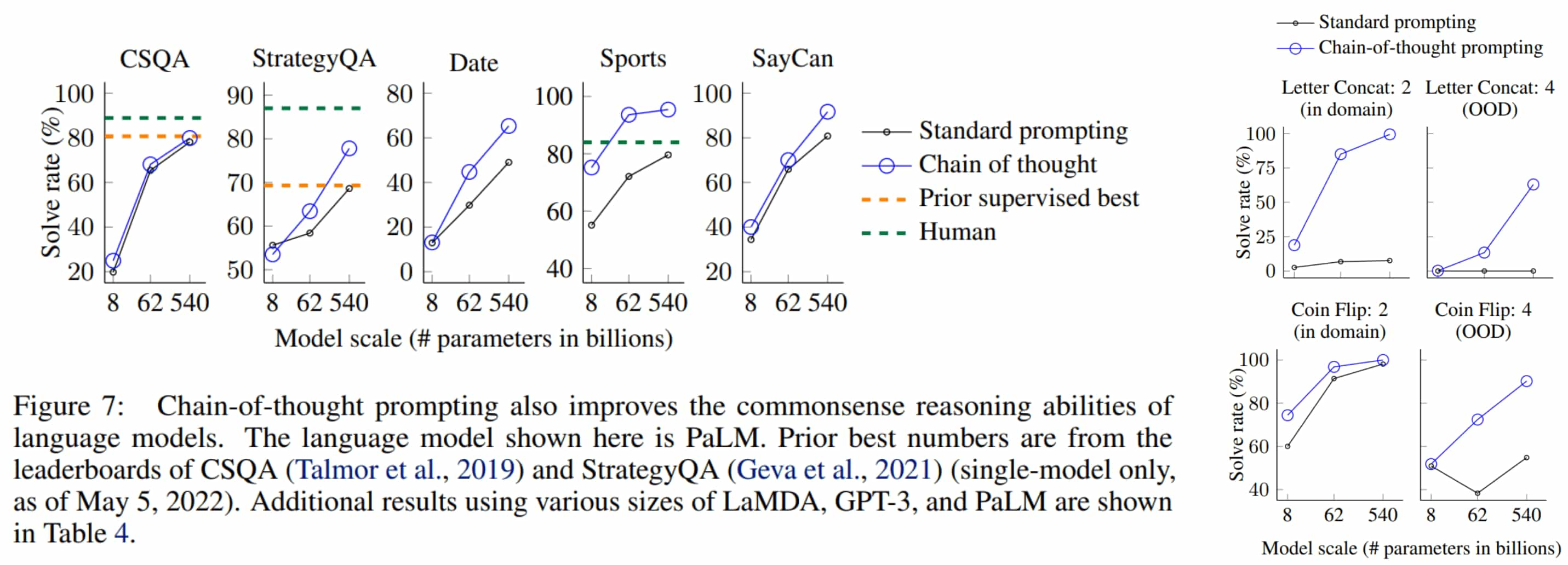
Why does CoT work?
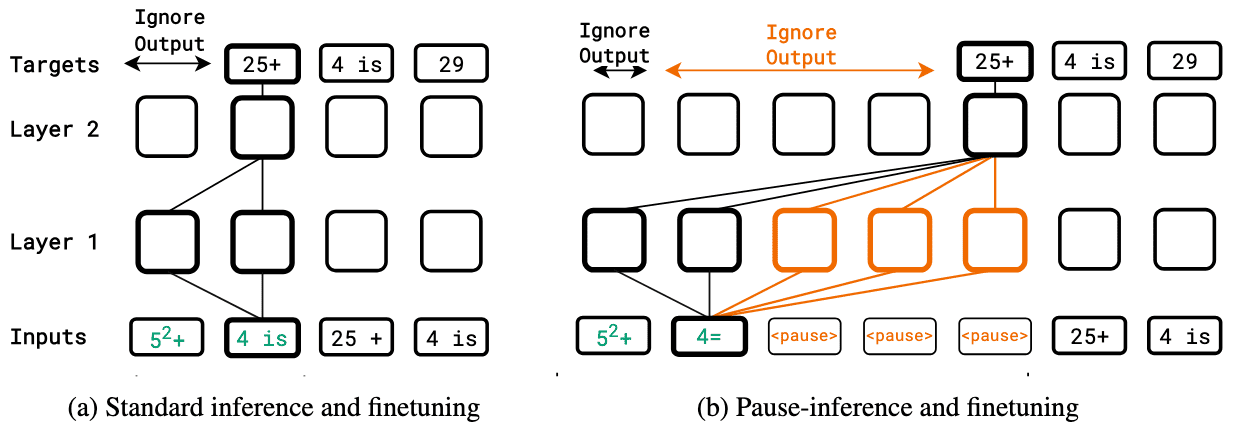
CoT is a powerful method for improving LLM accuracy on arithmetic and symbolic reasoning tasks, but its underlying mechanism remains unclear. Several studies (Goyal et al. 2024, Li et al. 2024) suggest that CoT enhances performance by refining the latent vector for predicting the answer, aided by additional computation and guidance from semantic tokens.
Transformer-based language models generate responses by producing a series of tokens sequentially. Formally, the $(K + 1)^\text{th}$ token is derived by manipulating $K$ hidden vectors (semantic tokens) per layer, with one vector per preceding token. Simply put, CoT allows the model to manipulate $K + M$ hidden vectors via $M$ thinking phases before producing the $(K + 1)^\text{th}$ token. This process increases expressivity by performing $K + M$ parallel computations, thereby expanding the computational width of the LLM.
For similar reason, Goyal et al. 2024 finds that introducing inference-time delays—by delaying the extraction of the model’s outputs—results in performance gains when the model is pretrained and fine-tuned with delays using a learnable $\texttt{
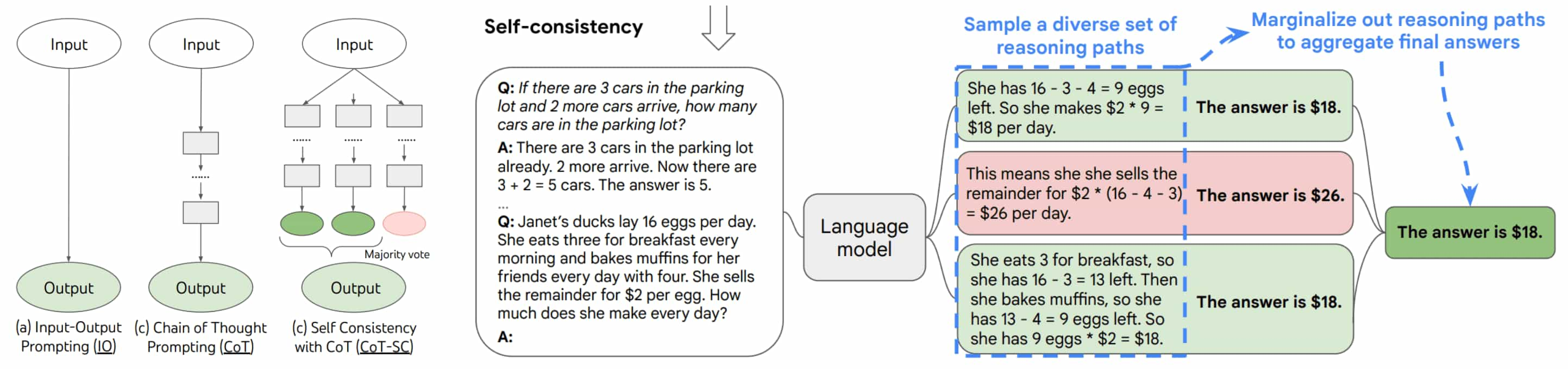
Ensembling (Self-Consistency)
LLMs often struggle with tasks that involve controversy or uncertainty, generating varying outputs for the same input prompt. To address this challenge, model ensembling for text generation has been widely explored in the NLP literature.
Let \(\{\mathbf{x}_1, \cdots, \mathbf{x}_K \}\) represent $K$ prompts for the same task. Given an LLM $\mathbb{P}(\cdot \vert \cdot)$, the best prediction for each prompt \(\mathbf{x}_i\) is obtained by \(\hat{\mathbf{y}}_i = {\arg \max}_{\mathbf{y}_i} \mathbb{P}(\mathbf{y}_i \vert \mathbf{x}_i)\). These predictions can be combined to form a “new” prediction:
\[\mathbf{y} = \texttt{Combine} (\hat{\mathbf{y}}_1, \cdots, \hat{\mathbf{y}}_K)\]where $\texttt{Combine}(\cdot)$ refers to the combination model, which can take various forms. A well-known implementation of this is self-consistency (majority voting), which selects the answer that aligns best with other predictions, rather than choosing the one with the highest probability.
- First, an LLM is prompted with CoT and generates multiple reasoning paths by sampling.
- Next, the frequency of each answer is counted across these reasoning paths.
- The final output is the answer with the highest frequency.
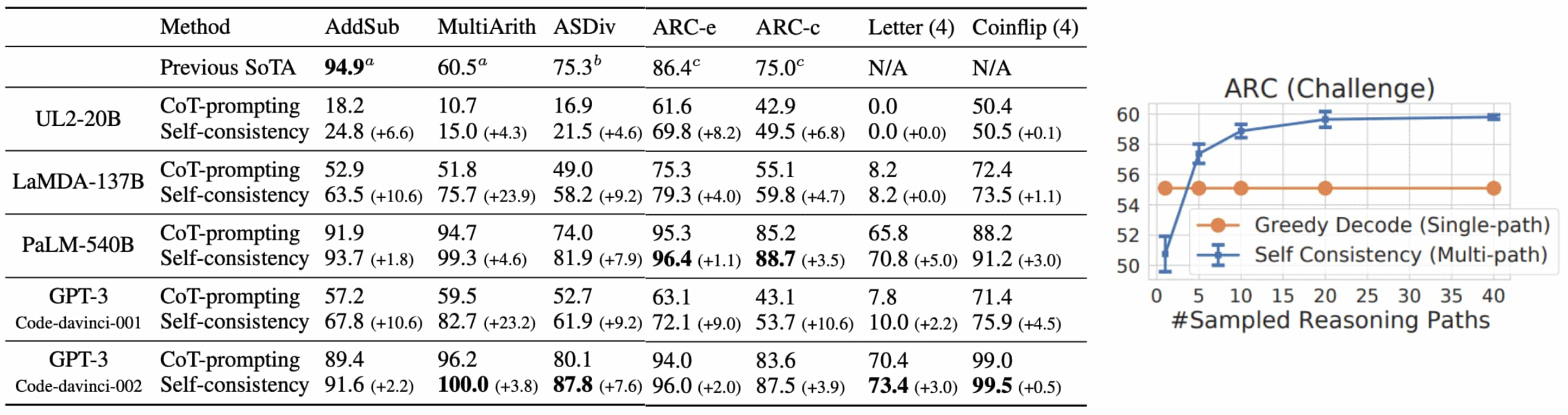
Self-consistency enhances CoT performance in tasks requiring complex reasoning by leveraging the intuition that a complex reasoning problem typically admits multiple paths, all leading to the correct answer. Moreover, performance improvements increase with a larger number of reasoning paths ($K$), across various arithmetic and commonsense reasoning benchmarks.
Tree-of-Thought (ToT)
CoT is currently one of the most active areas in prompt engineering. It has not only enhanced LLM performance but also paved the way for a variety of methods to study and verify the reasoning abilities of LLMs. However, in practice, CoT prompting falls short for tasks requiring exploration and strategic lookahead. While self-consistency improves CoT performance for complex reasoning, it aggregates reasoning paths based solely on the final answer, not the intermediate steps. To address this limitation, Tree-of-Thought (ToT), proposed by Yao et al. 2023, explores multiple reasoning paths over intermediate thoughts.
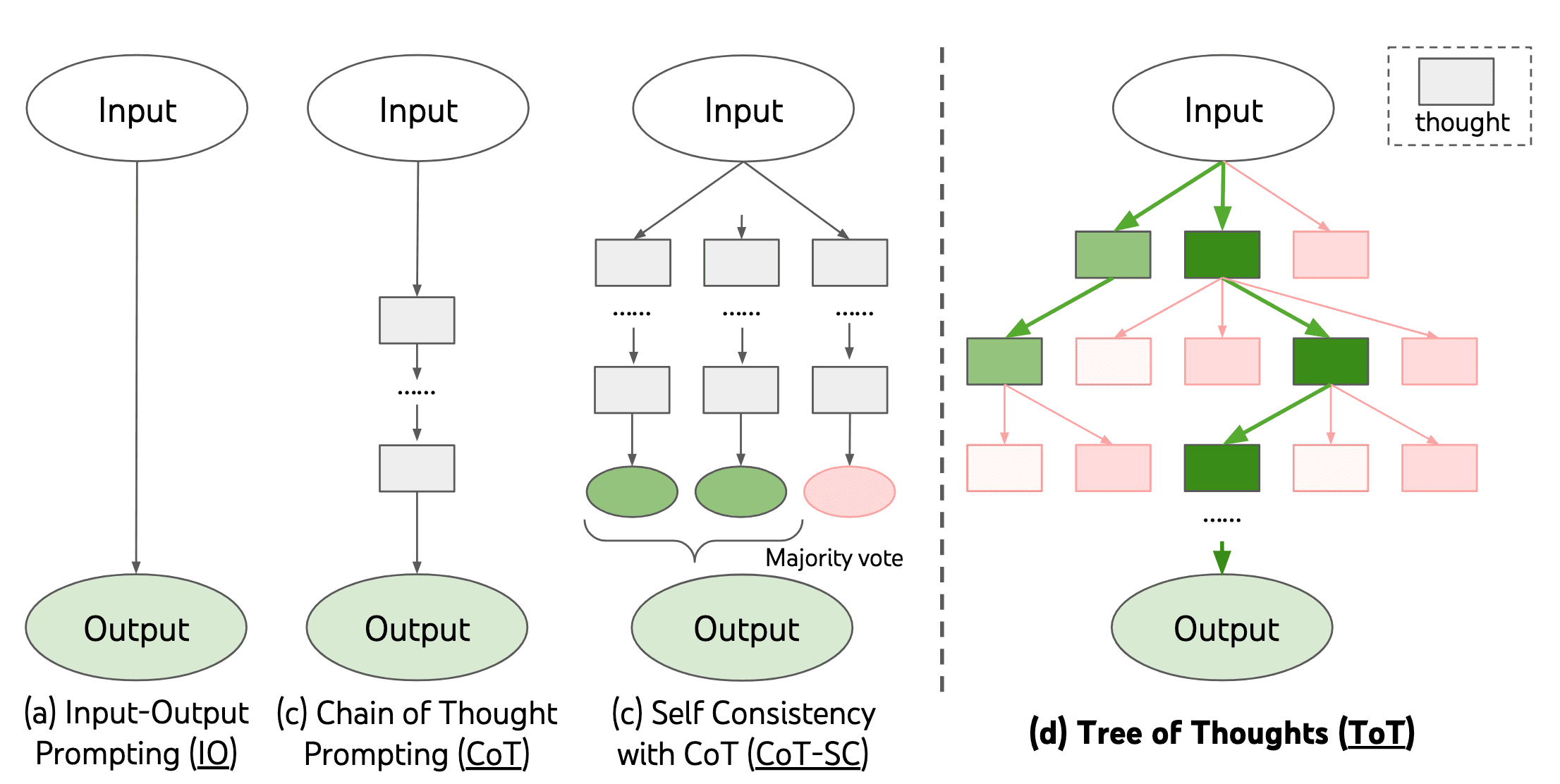
ToT involves $4$ intermediate steps:
- Thought Decomposition
Decide the "unit" of the "thought" (e.g., paragraph, word). Depending on the problem, a thought could be a few words (e.g., Crosswords), a line of an equation (e.g., Game of 24), or a whole paragraph (e.g., Creative Writing). - Thought Generator
Generate the $K$ "thoughts" by sampling based on the given prompt. - State Evaluator
Evaluate the state by voting by LLMs (similar to self-consistency).
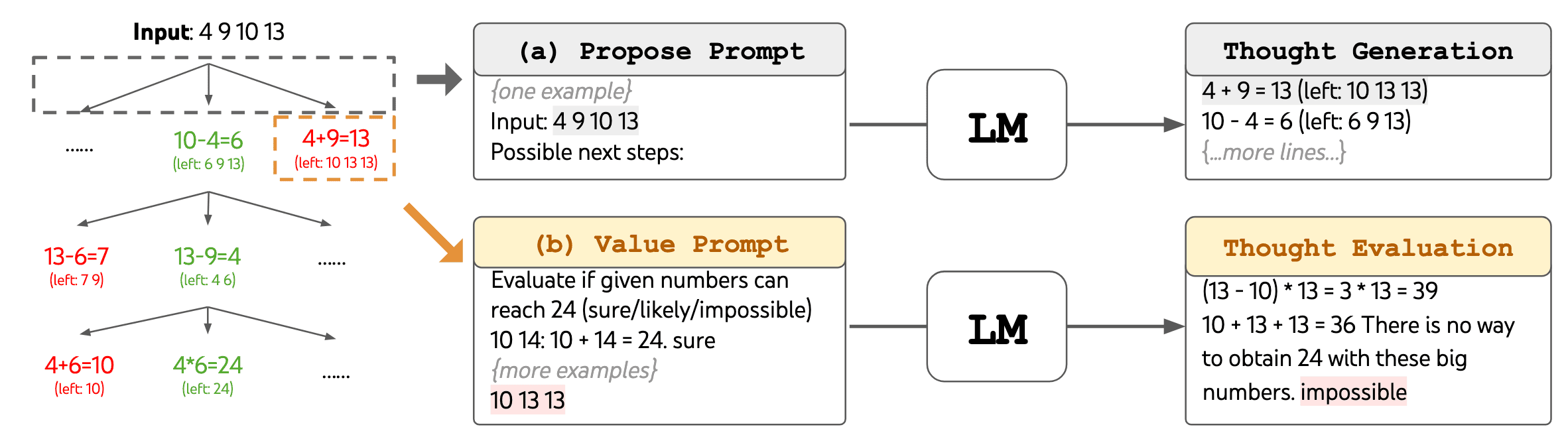
$\mathbf{Fig\ 10.}$ The LM is prompted for (a) thought generation and (b) state evaluation. (Yao et al. 2023) - Search
Search over the thoughts by BFS or DFS.- Breadth-first search (BFS)
Maintain a queue of the $B$ most promising states per step. From the queued path, generate another $K$ candidate thoughts and update the queue. - Depth-first search (DFS)
Explore the most promising state first, until the final output is reached or the state evaluator deems the current path unsolvable.
- Breadth-first search (BFS)


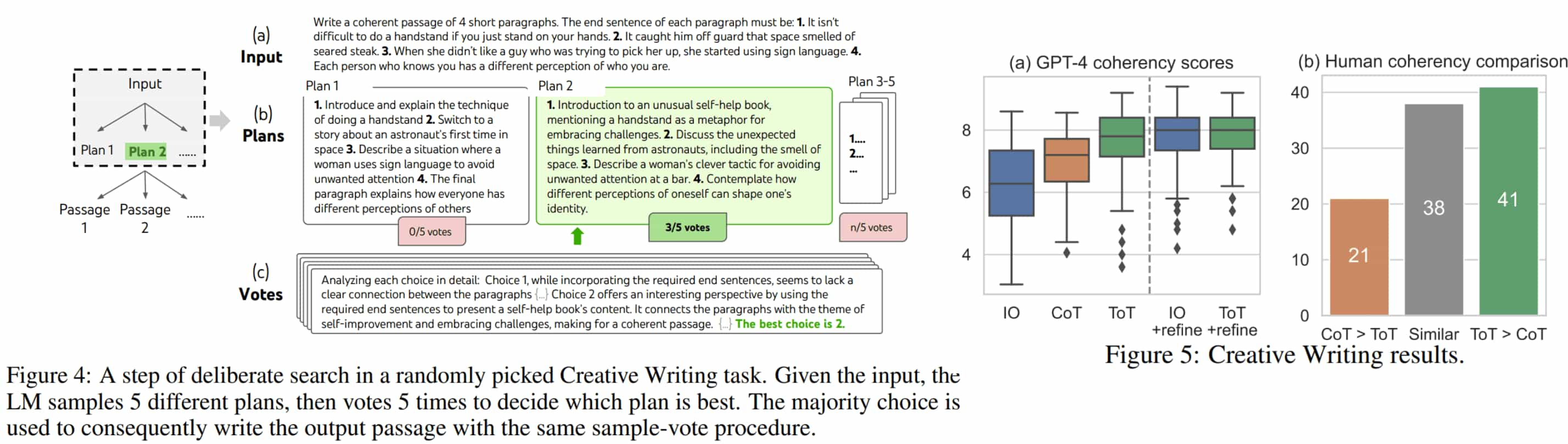
ToT significantly enhances not only LLM problem-solving abilities but also its coherency. In a user study, humans preferred ToT over CoT in $41$ out of $100$ passage pairs, while CoT was favored in only $21$, showing that ToT produces more coherent passages than both IO (zero-shot prompt) and CoT.
Retrieval-Augmented Generation (RAG)
Storing all world knowledge within a language model (parametric memory) requires an enormous model size, and updating or expanding knowledge in such a model is challenging (e.g., daily updates). To enhance language model performance on knowledge-intensive tasks, such as open-domain question answering, retrieval-augmented generation (RAG) is often employed. When standard LLMs, which rely solely on pre-trained knowledge, fall short in accuracy and depth, RAG integrates a language model (parametric memory) with an external database (non-parametric memory). By accessing external databases and documents, RAG significantly improves the quality of responses, ensuring they are contextually relevant and factually accurate. This approach is especially valuable in tasks demanding high factual precision and up-to-date information.
Standard RAG framework
The key steps of standard RAG involve:
- External Database
Prepare a collection of texts which are treated as an additional source of knowledge we can access. - Retriever
Retrieve relevant texts for a given query with similarity metrics, such as inner product (Maximum Inner Product Search). Usually, rule-based retrievers such as TF-IDF or BM25 are enough. - Generator
Input both the retrieved texts as context and the query into an LLM, which is then prompted to produce the final prediction. To further improve RAG, it is also possible to fine-tune LLM.
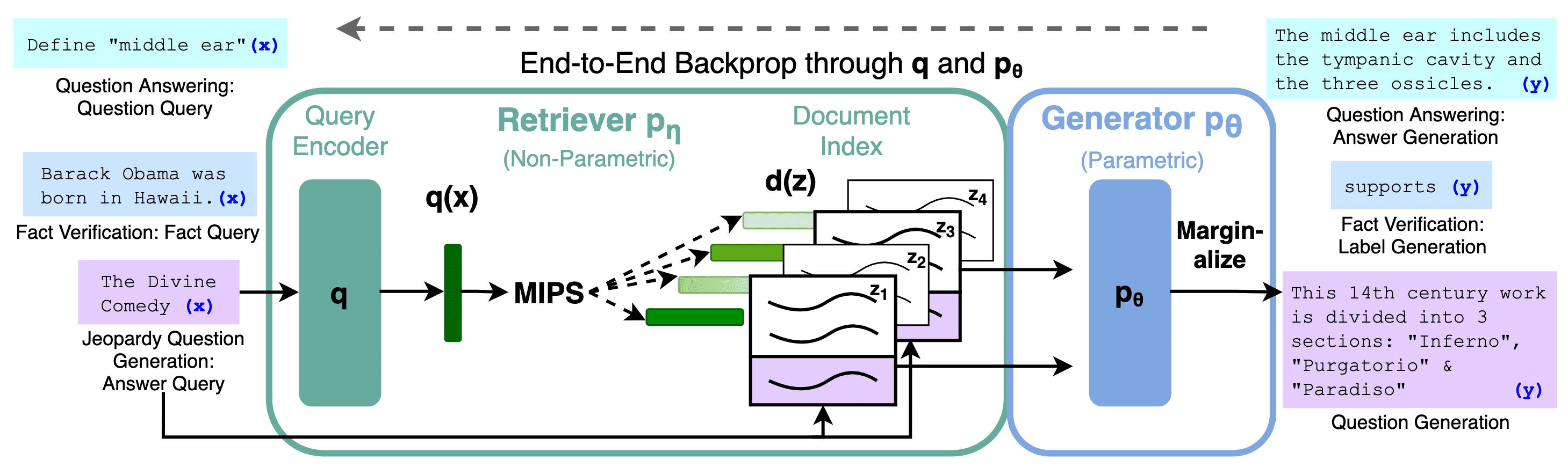
Therefore, RAG divides problem-solving into two key steps. First, relevant and supporting information is gathered from various knowledge sources for a given query. In the second step, LLMs generate responses based on the collected information. This integration extends LLM capabilities by enabling interaction with, and in certain contexts, the ability to influence or control external systems. As a result, LLMs operate more as autonomous agents rather than simply as text generators.
In-Context RAG
RAG was initially proposed before the advent of LLMs, and purely relying on LMs for knowledge-intensive tasks perform poorly. Thus, modifying the LM architecture—such as through training or fine-tuning to integrate external information—was necessary, which complicated deployment. With the advent of in-context learning in LLMs, in-context RAG, proposed by Ram et al. 2023, avoids changing the parameter and prepends grounding documents to the input. This requires no further training of the LM. The core idea is to use retrieved documents as in-context prompts.

n their experiments, the authors demonstrated that LLM with in-context RAG provide performance gain in language modeling and open-domain question answering. Furthermore, retrieving the top-$k$ documents using BM25, followed by re-ranking with other LLMs, can further enhance performance. Notably, large LMs are not required for re-ranking, as illustrated in the figure below:

Graph RAG
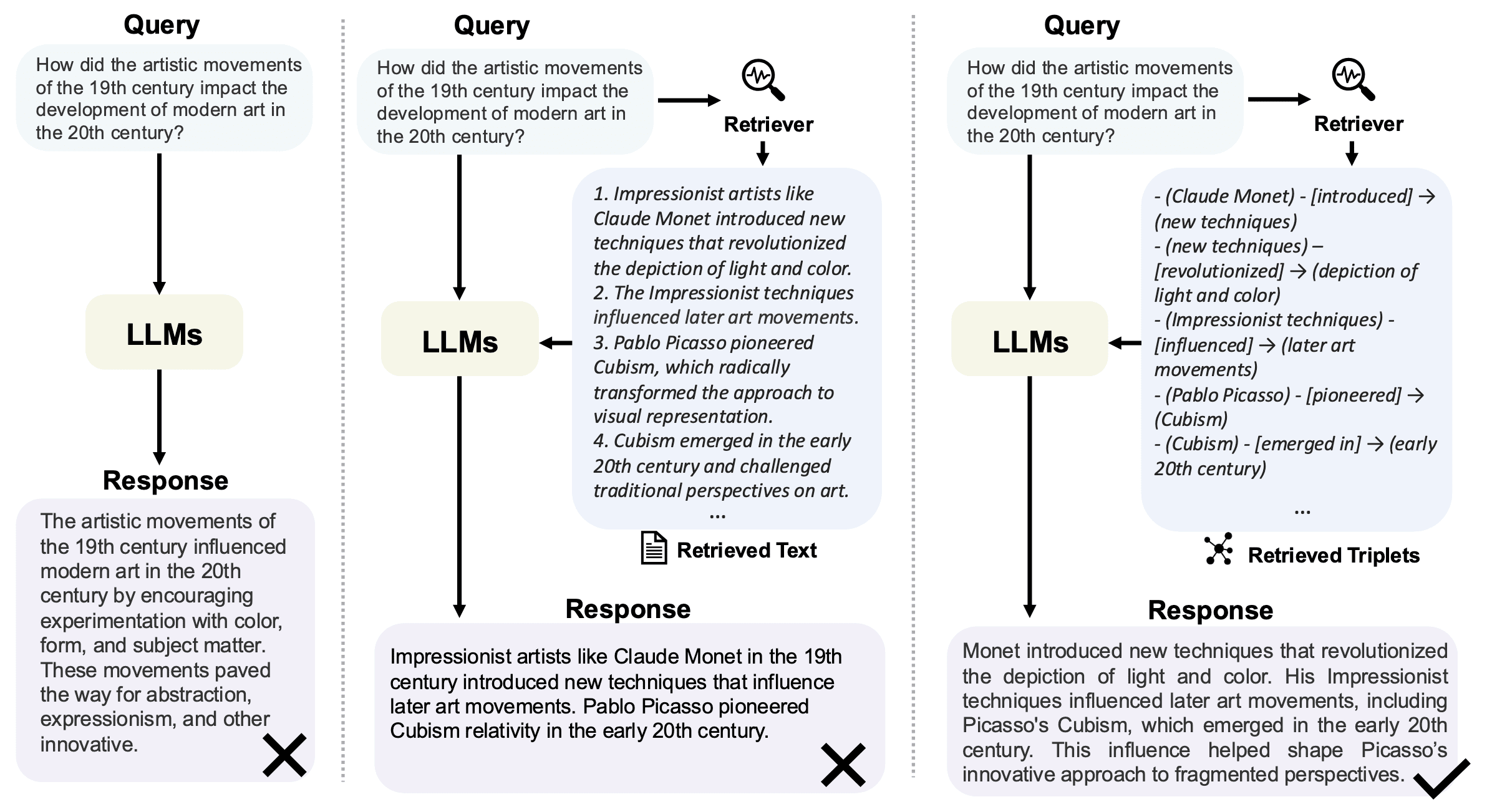
Big data management is not merely about storing vast amounts of data; it’s about extracting meaningful insights, uncovering hidden patterns, and making informed decisions. Depending on the task, there are two primary options for designing databases: vector databases (non-relational database), such as FAISS, and graph databases (relational database), such as Neo4j. Vector databases are good for similarity searches, while graph databases are good for navigating relationships.
While RAG has delivered impressive results and is widely applied across various domains, it encounters limitations in real-world scenarios. Traditional RAG struggles to capture significant structured relational knowledge that cannot be represented through semantic similarity alone. Graph Retrieval-Augmented Generation (GraphRAG) offers an innovative solution to these challenges. Unlike traditional RAG, GraphRAG retrieves graph elements containing relational knowledge relevant to a given query from a pre-constructed graph database.
References
[1] Xiao et al. “Foundations of Large Language Models”, arXiv:2501.09223
[2] OpenAI: Brown et al. “Language Models are Few-Shot Learners”, arXiv:2005.14165
[3] Google Brain: Wei et al. “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models”, NeurIPS 2022
[4] Goyal et al. “Think before you speak: Training Language Models With Pause Tokens”, ICLR 2024
[5] Li et al. “Chain of Thought Empowers Transformers to Solve Inherently Serial Problems”, ICLR 2024
[6] Google Brain: Wang et al. “Self-Consistency Improves Chain of Thought Reasoning in Language Models”, ICLR 2023
[7] Google Deepmind: Yao et al. “Tree of Thoughts: Deliberate Problem Solving with Large Language Models”, NeurIPS 2023
[8] Lewis et al. “Retrieval-Augmented Generation for Knowledge-Intensive tasks”, NeurIPS 2020
[9] Ram et al. “In-Context Retrieval-Augmented Language Models”, ACL 2023
[10] Peng et al. “Graph Retrieval-Augmented Generation: A Survey”, ACM 2024
Leave a comment