
[NLP] BERT
According to outstanding performance of Transformer compared to RNN, it is natural to replace RNN in language model pre-training by Transformer.
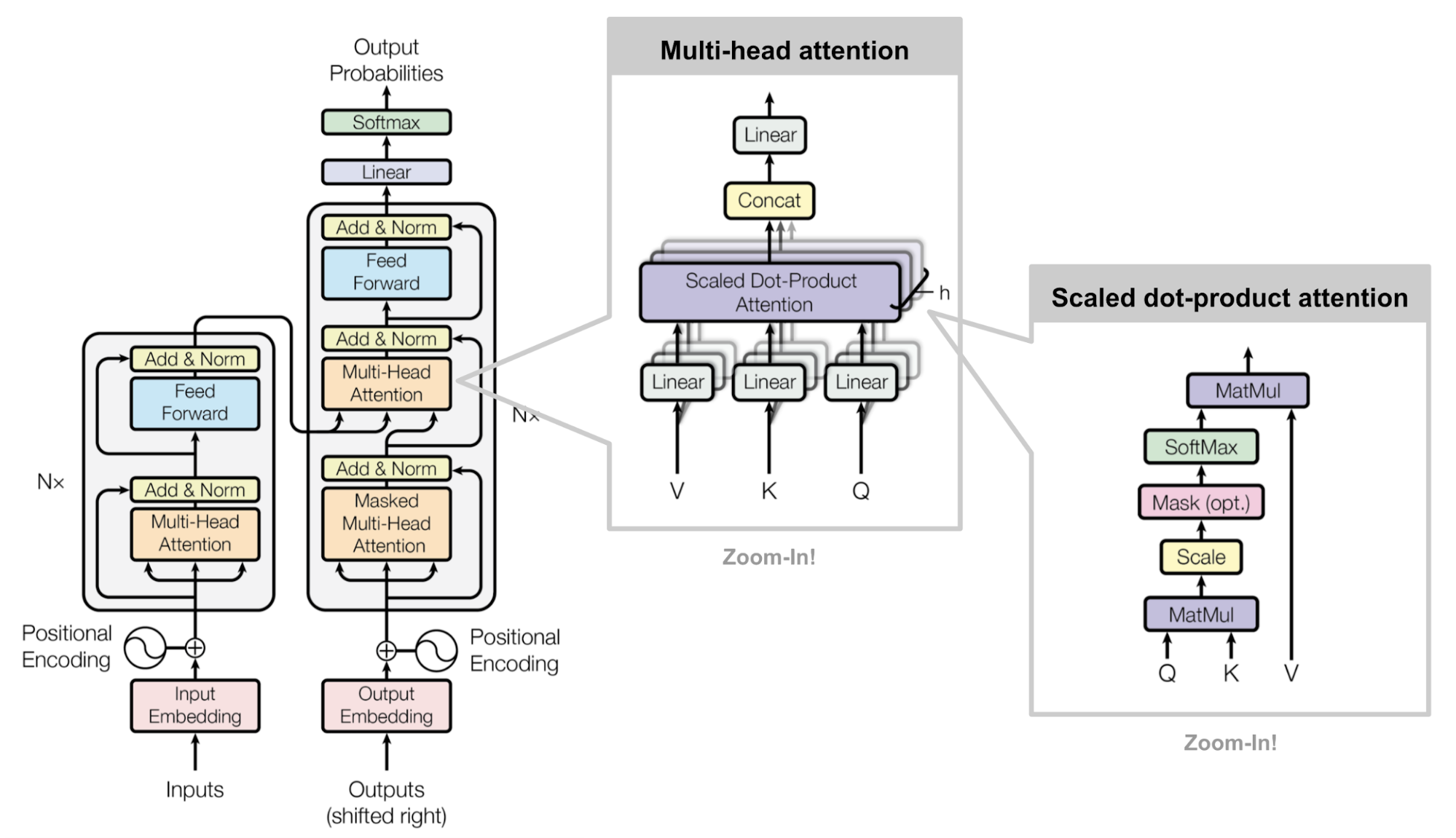
Recall: Overall architecture of Transformer (source)
Like ELMo, suppose that we want to train a bidirectional language model via next word prediction task. And recall that the vanilla Transformer has a direction for generating a sentence as a result of masking future tokens, masked multi-head attention, so we are required to discard this masking. (We might train two transformers for each forward and backward prediction, but it is not very good idea in terms of inefficiency.) The issue if we were to remove masking is that Transformer may cheat to predict the next word, since the answers are already revealed to the model via self-attention layer. How can we use a Transformer for language model pre-training, but looks both direction’s contexts?
Masked Language Model (MLM)
Bidirectional Encoder Representations from Transformers (BERT), proposed by Devlin et al. 2018, handles the constraint arised from masked self-attention in decoder by masked language model (MLM). It randomly masks input tokens and is trained to predict the original word masked based on the entire context:
-
Input:
"I [MASKED] therefore I [MASKED]"
-
Target:
"I think therefore I am"
So we don’t have to shift the input sentence as a target, and it doesn’t yield any violations for proper language model. Simultaneously, the objective of the task forces the model to learn better representations that contains both left and right context, which allows us to pre-train a deep bidirectional Transformer.
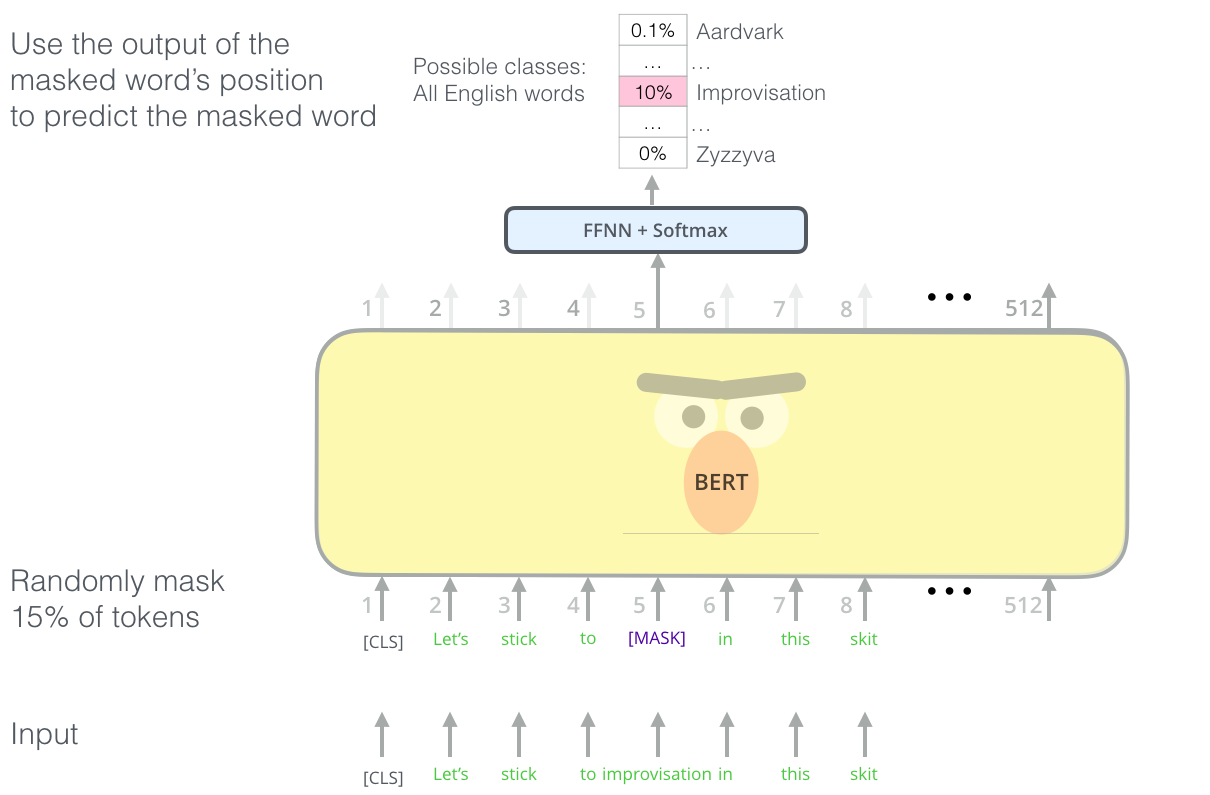
$\mathbf{Fig\ 1.}$ Masked Language Model (source: Jay Alammar)
BERT
BERT is basically a multi-layer bidirectional Transformer encoder, and there are total two steps in BERT framework:
-
Pre-training
- trained on unlabeled data over 2 tasks
- Task #1: Masked LM
- Task #2: Next Sentence Prediction (NSP)
- trained on unlabeled data over 2 tasks
-
Fine-tuning
- using labeled data from the downstream tasks
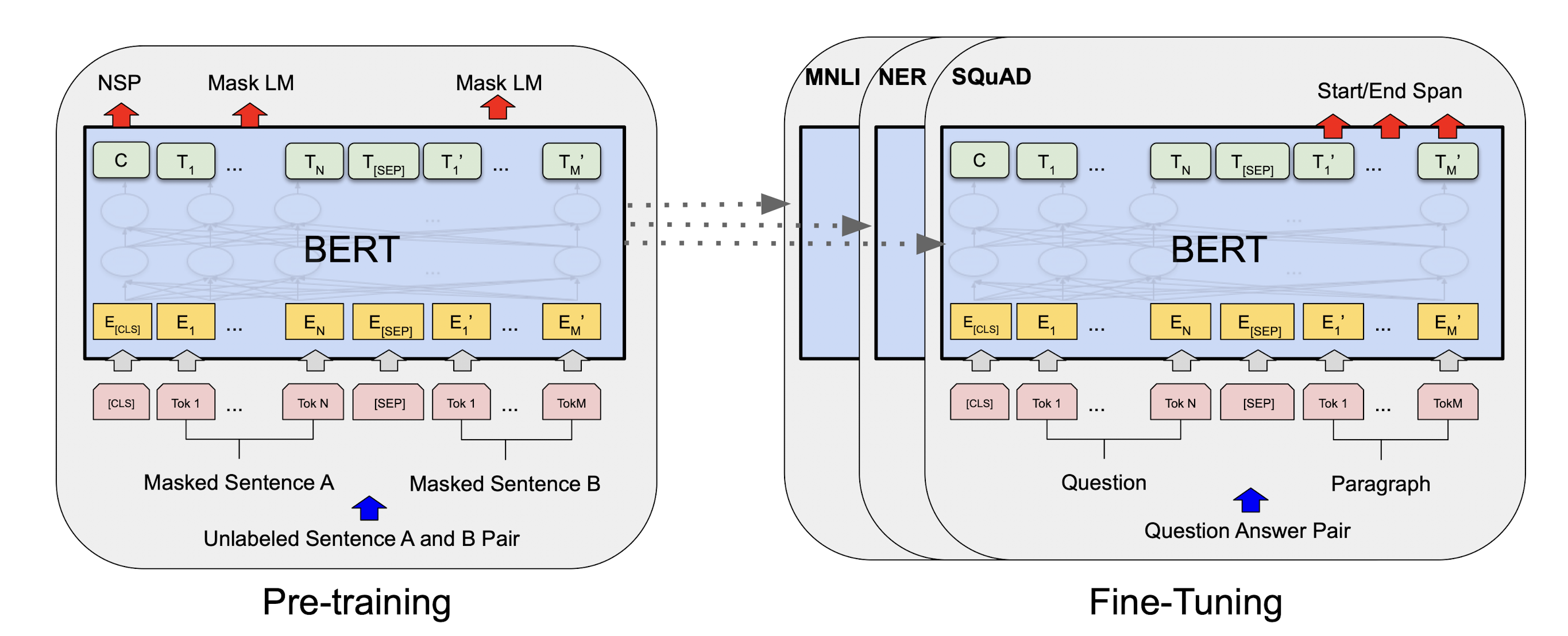
$\mathbf{Fig\ 2.}$ Overall framework for BERT (source: Devlin et al. 2018)
Input representation
-
Pair of two sentence
input of BERT consists of two sentences
- for generalizability to various downstream task
-
Since many tasks associate pairs of sentences, e.g.
- quetion-answer
- paragraph-summary
- English-French
-
Since many tasks associate pairs of sentences, e.g.
-
starts with classification token
[CLS] -
pairs are combined into a single sentence, but differentiated by token
[SEP]and segment embeddings
- for generalizability to various downstream task
-
Embedding
Input embeddings for BERT can be divided into 3 parts:
- Token Embeddings (WordPiece embeddings)
-
Segment Embeddings
- indicate whether a token belongs to sentence
Aor sentenceB
- indicate whether a token belongs to sentence
-
Position Embeddings
- also learned, not position encoding
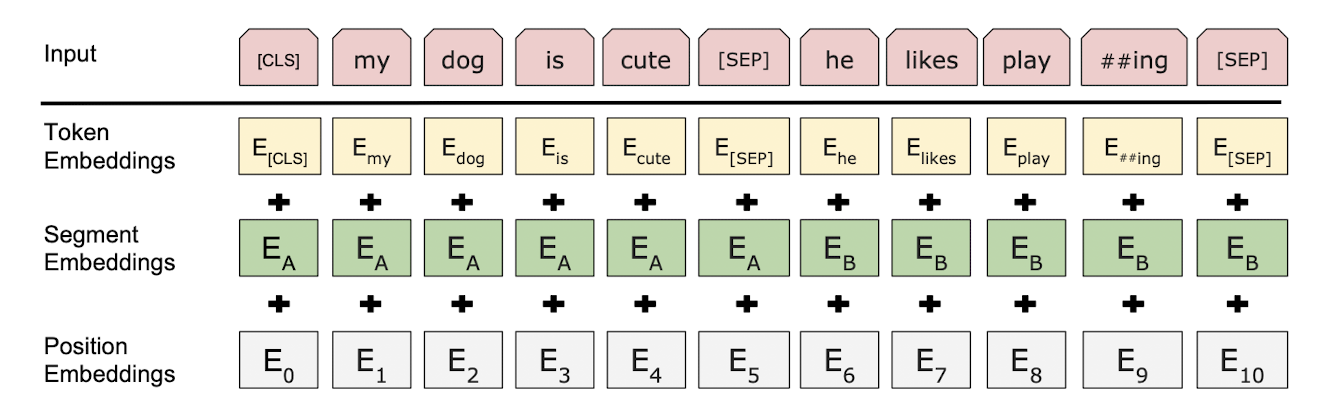
$\mathbf{Fig\ 3.}$ BERT input representation (source: Devlin et al. 2018)
Pre-training tasks
In order to obtain not only bi-directional contextualized word-level but also sentence-level representations, BERT is pre-trained over 2 tasks simultaneously. And it turned out that each configuration of BERT plays a crucial role in part to it’s outstanding performance:
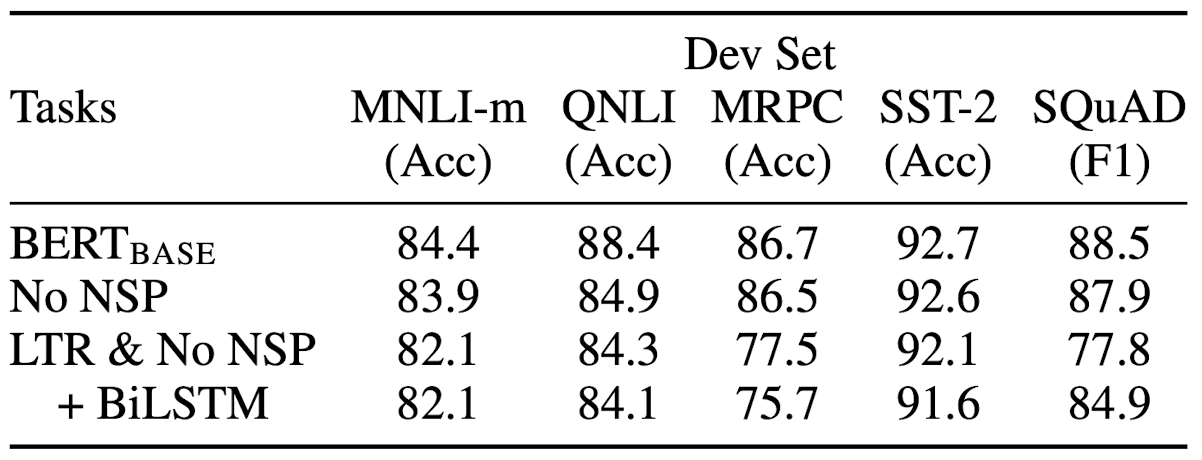
$\mathbf{Fig\ 4.}$ Ablation over the pre-training tasks (source: Devlin et al. 2018)
Task #1: Masked LM
WordPiece embeddings are randomly masked about 15%, and then only predicts the corresponding missing words of modified tokens. A downside is discrepancy between pre-training and fine-tuning, since [MASK] token doesn’t appears in fine-tuning period. Hence, BERT replaces 15% of input words by
-
[MASK]with 80% probability - a random word with 10% probability
- itself (i.e. does not replace and keep it) with 10% probability
So this task encourages BERT to learn context-dependent word-level representation.
More formally, the model is trained in unsupervised way to minimize the negative log pseudo-likelihood
\[\begin{aligned} \mathcal{\Theta} = \mathbb{E}_{\mathbf{x} \sim \mathcal{D}} \mathbb{E}_{\mathcal{M}} \sum_{i \in \mathbf{m}} - \text{ log } p(x_i \mid \mathbf{x}_{- \mathbf{m}}) \end{aligned}\]where $\mathbf{m}$ is a random binary mask, and \(\mathbf{x}_{- \mathbf{m}}\) stands for masked input sentence. Note that the conditional probability is computed by a softmax of last layer’s hidden vector \(\mathbf{h}(\mathbf{x}_{- \mathbf{m}})\):
\[\begin{aligned} p(x_i \mid \mathbf{x}_{- \mathbf{m}}) = \frac{\text{exp}(\mathbf{h}_i(\mathbf{x}_{- \mathbf{m}})^\top \mathbf{e}(x_i) )}{\sum_{x^\prime} \text{exp}(\mathbf{h}_i(\mathbf{x}_{- \mathbf{m}})^\top \mathbf{e}(x^\prime) )} \end{aligned}\]where $\mathbf{e}(x)$ is the embedding for token $x$.
Task #2: Next Sentence Prediction (NSP)
This task stems from the fact that many crucial tasks such as Q&A require the understading of sentence-level relationship. To force BERT to learn sentence-level representations, the authors harnessed an additional binary classification if one sentence follows another.
-
For sentence pair
AandB,-
Bactually followsAwith 50% probability -
Brandomly selected (doesn't followA) with 50% probability
-
-
predict a binary label $C$ that indicates whether
Ais followed byB
Purpose of [CLS] Token
[CLS] stands for classification. Recall that BERT encoder generates a sequence of hidden states (word representations). For classification tasks (e.g. sentiment classification), it is necessary to distill this sequence into a single vector. Various methods exist to this conversion. For instance, it is feasible to design BERT to output a single number as a probability. However, BERT is concurrently trained on multiple tasks. To organize inputs and outputs in such a format (with both [MASK] and [CLS]) assists BERT in learning both tasks simultaneously, contributing to enhanced performance.
In classification tasks, the BERT encoder output of [CLS] can be trained to encapsulate the sentence-level representation or class label for classification purposes.
Fine-tuning approach
After pre-training BERT, it can be fine-tuned in an end-to-end supervised manner for a variety of downstream tasks. The figure below illustrates fine-tuning BERT on different tasks:
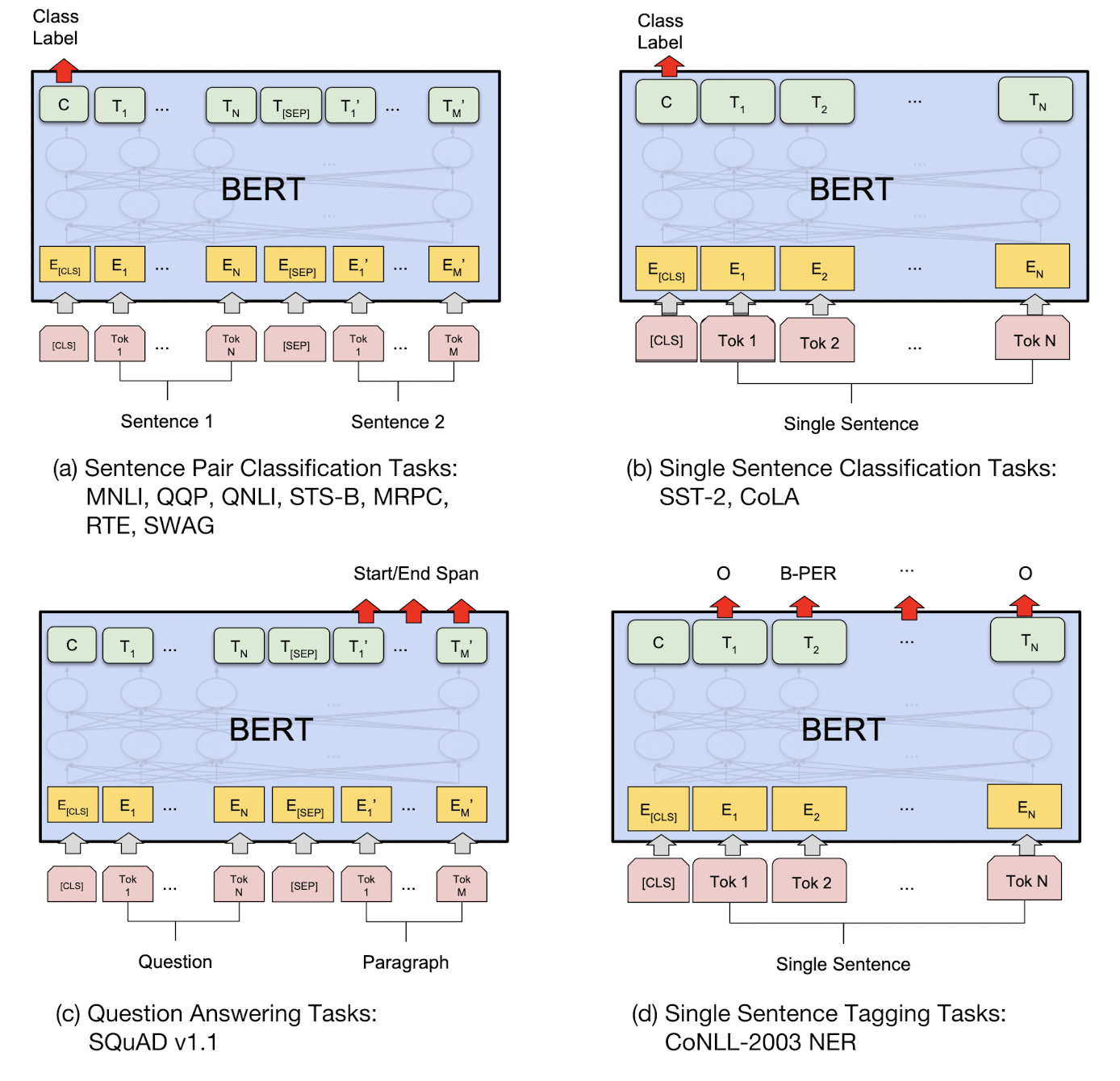
$\mathbf{Fig\ 5.}$ BERT applications (source: Devlin et al. 2018)
And BERT achieved the state-of-the-art performance on many NLP tasks.
Feature-based approach
But not all NLP tasks can be easily represented by a Transformer architecture. In that case, just like with ELMo, the features of pre-trained BERT can be pulled out for that tasks (without fine-tuning).
The authors explored various combinations of intermediate features of BERT for task:
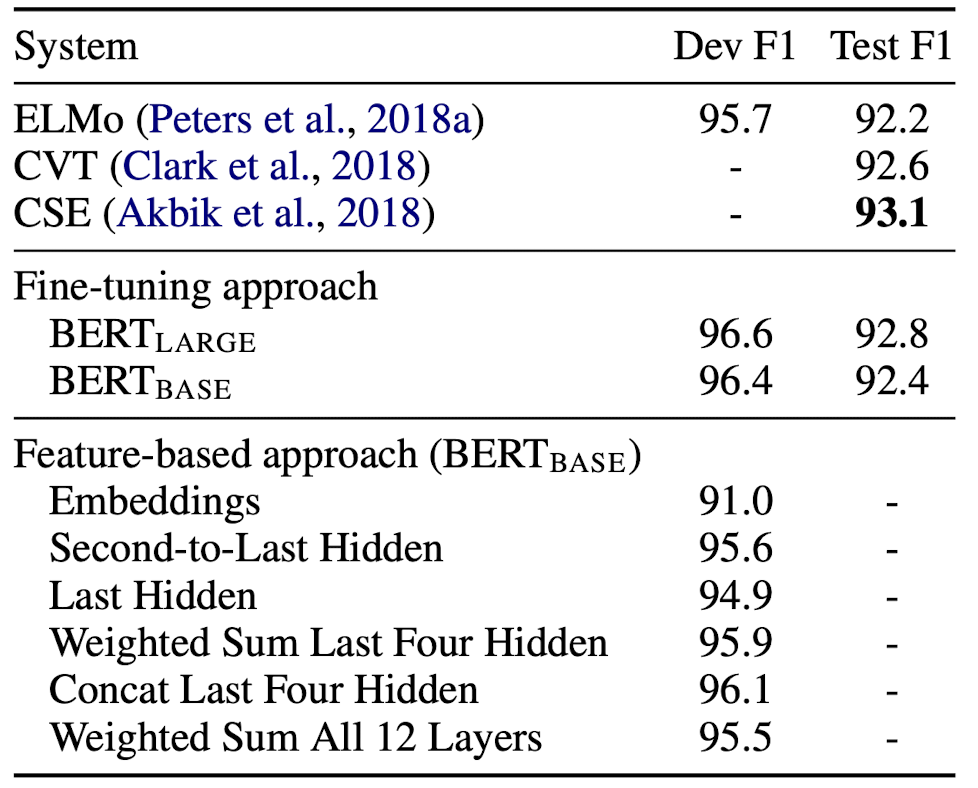
$\mathbf{Fig\ 6.}$ Result of feature-based appraoch (source: Devlin et al. 2018)
under CoNLL-2003 Named Entity Recognition (NER) task that is to identify and classify named entities in a text, for example,

Reference
[1] Devlin et al., Pre-training of Deep Bidirectional Transformers for Language Understanding, NAACL 2019
[2] UC Berkeley CS182: Deep Learning, Lecture 13 by Sergey Levine
[3] Kevin P. Murphy, Probabilistic Machine Learning: An introduction, MIT Press 2022.
[4] What is purpose of the [CLS] token and why is its encoding output important?, Datascience stackexchange.
Leave a comment